这本书从基因的角度出发, 将自然界生物的各种行为现象解释为基因延续的策略表现.
总结一句话核心观点:
基因不仁,以生物为刍狗。
理查德·道金斯
信之则有, 不信则无.
怎么这种玩逻辑的好像都有这个问题, 上一个是罗素.
前言
好长的前言…
本书中基因的定义来自种群进化生物学家乔治·C.威廉斯,他已然仙逝,但无疑是本书的英雄。同样离我们而去的还有约翰·梅纳德·史密斯和比尔·汉密尔顿。威廉斯认为:“基因是染色体材料上任何一个可能存在得足够长久的代际,并且是可以当作自然选择的单位的部分。”我从这个定义中得出了一个多少有些好笑的结论:“严格来讲,这本书的书名应该是……《染色体有点自私的一大部分以及更为自私的一小部分》。”胚胎学家关心的是基因会如何影响表型,我们新达尔文主义者的关注点则是实体在种群中的频度发生的改变。这些实体在威廉斯看来就是基因(威廉斯后来称之为“抄本”)。基因是可以计数的,而其出现频度是其成功与否的一种测度。本书的一个核心思想是:生物个体不具备上述讨论的基础。单个生物体的基因频度都是100%,因而无法“当作自然选择的单位”。
基因角度的亲缘关系
很多西方人可能不知道自己与女王的亲缘关系其实比十五重还近,我亦如此,门口的邮递员也是如此。有很多种方法可以让我们成为某个人的远房表亲,或者让我们都成为彼此的亲戚。我知道自己是妻子的十二重堂兄弟姐妹的 孙辈(共同祖先是乔治·黑斯廷,第一代亨廷顿伯爵,1488—1544),但是很有可能我们还能通过某种未知的不同方式成为血缘关系更近的亲戚(从各自祖先查下来的不同路径),而且绝对还有许多其他的方式让我们成为血缘关系更远的亲戚。我们所有人都是如此。你和女王可能既是九重堂兄弟姐妹的六世孙辈,又是二十重堂兄弟姐妹的玄孙辈,还是三十重堂兄弟姐妹的八世孙辈。我们所有人,无论生活在世界上的哪个地方,不仅仅是彼此的远房亲戚,而且还有几百种连接亲缘关系的路径。
如果你不断乘以2,一直计算到征服者威廉的年代,你的(以及我的、女王的、邮递员的)祖先数量将至少是个十亿数量级的数字,比当时全世界的人口数量还多。这个计算本身就证明,无论你是从哪里来的,我们都共同拥有许多祖先(如果回溯到足够久远的过去,我们的祖先都是完全相同的),所以我们彼此也是很多不同形式的亲戚。
第一步:分子钟——用“突变”来计算“时间”
首先,我们要解决**“差异如何换算成时间”**的问题。
你的DNA是由大约30亿个碱基(A、T、C、G)组成的密码长链。每当你父母的细胞分裂产生精子或卵子时,这套密码都要被复制一次。在复制过程中,偶尔会出现极个别的“抄写错误”(比如把A抄成了G),这就是突变。
科学家发现了一个规律:在漫长的演化史中,DNA上中性突变(对生存没有好坏影响的突变)的积累速度是相对恒定的。 这种恒定的突变率就像大自然钟表上滴答作响的秒针,被称为分子钟。
计算原理:
假设人类的突变率是:每1万年,某段特定的DNA序列上平均会积累1个突变。
现在,我们把你父亲给你的某段DNA,和你母亲给你的对应段DNA放在一起对比:
- 如果发现它们之间有 2个 差异。
- 这就意味着,从它们上一次是“同一个DNA”(共同祖先)开始,这两支血脉分别各自演化,各自积累了1个突变(1+1=2)。
- 既然积累1个突变需要1万年,科学家就能断定:你父母的这段基因,在距今1万年前,来自于同一个远古祖先。 这个相遇的时间点,就是**“聚结点”**。
通过数差异,科学家就能精确算出任意两段等位基因的“聚结时间”。
第二步:基因重组——一个人体内藏着“千万个不同的祖先”
如果整个基因组的聚结时间都一样,那我们只能算出一个时间点,这无法写出一部历史。李恒和德宾的模型之所以神奇,是因为基因组是会被“打碎重组”的。
当你的祖祖辈辈在繁衍时,精子和卵子的形成过程中会发生**“染色体交叉互换”(基因重组)**。也就是说,你爷爷和你奶奶的染色体在传给你爸爸的时候,不是原封不动传递的,而是会像洗牌一样被打断、拼接。
经过几万、几十万年的“洗牌”,你体内的染色体早就是一个由无数个“小片段”拼接而成的马赛克了。
- 片段A 可能在 1万年前 找到了共同祖先(比如某个远古非洲猎人)。
- 片段B 因为没有被洗进那个猎人体内,只能继续往上追溯,直到 10万年前 才找到共同祖先。
- 片段C 可能要追溯到 50万年前。
关键结论: 虽然你只是一个人,但你的基因组被天然地切成了成千上万个独立的小片段。每一个小片段,都记录了一个独立的历史时间点。 统计这成千上万个时间点,科学家手里就有了极大量的历史数据样本。
第三步:溯祖理论——从“时间分布”推断“人口规模”
现在,科学家手里拿到了一张图表,上面密密麻麻标满了你体内这几万个基因片段发生“聚结”的时间点。怎么从这些时间点,看出当时的人口数量呢?
这就用到了统计学上的溯祖理论。逻辑非常直观,我们可以用“村庄找亲戚”来打比方:
情景1:人口极少的时期(种群瓶颈)
假设在距今7万年前,因为火山爆发,地球上只剩下极少数的人类(比如几千人)。
因为当时“人口池”非常小,你的各种远古祖先们在那个时代极其容易**“碰见并共用同一个祖先”**。
- 结果: 科学家会在图表上发现,你体内有异常多的基因片段,它们的聚结时间都集中在“7万年前”这个节点。
- 推断: 大量基因在同一时期扎堆找到共同祖先 → 说明当时祖先极少,基因没得选 → 推断出当时发生了人口大衰减(种群瓶颈)。
情景2:人口繁盛的时期(种群扩张)
假设在距今20万年前,气候温暖,你的祖先有几百万人。
因为人在茫茫人海中,随机挑两个基因片段,它们恰好来自同一个人的概率非常极度低。它们只能继续向更古老的年代去寻找共同祖先。
- 结果: 科学家会发现,落在“20万年前”这个时间点的聚结片段非常稀少。
- 推断: 很难在这个时期找到共同祖先 → 说明当时人口基数极大 → 推断出当时种群非常繁盛。
总结
这套方法的精妙之处在于:
- 用 DNA的突变数量(分子钟) 算出每个基因片段“相遇”的年代;
- 利用 基因重组的特性,在一个人的身体里提取出成千上万个这样的年代数据;
- 统计这些年代数据的 密集程度(溯祖概率),反向推断出每一个历史时期祖先群体的人口规模。
这就是李恒和德宾的 PSMC模型(Pairwise Sequentially Markovian Coalescent)的大致原理。
Interesting
死亡的基因之书
基因视角还可能以其他方式穿透历史的迷雾吗?我在几本书中曾经提出了一个想法,我称之为“死亡的基因之书”。一个物种的基因库就是相互支持的基因的联合体,它们曾经一起在过去的特定环境中存活了下来,有久远的过去,也有近世的牵绊,这就使得它们成为那些环境的一种相反印记。如果一个遗传学家具备足够的知识,就应该能够从一种动物的基因组中读出该物种曾经生活的这些环境的特征。理论上来讲,欧洲鼹鼠(Talpa europaea)的DNA应该能够生动地展示出地下世界的面貌,那是一个位于地表之下的潮湿、黑暗的环境,空气中满是蠕虫、腐叶、甲虫幼虫的气味。如果我们知道如何去阅读的话,单峰骆驼(Camelusdromedarius)的DNA将会展现出用编码描绘的古老沙漠,那里有着沙尘暴、沙丘,以及生命对水的渴望。常见的宽吻海豚(Tursiops truncatus)的DNA表达着“深海水域”“快速追逐鱼类”“躲避虎鲸”等信息,不过是以一种我们在未来的某一天可能予以解读的语言写就的。但是同样的海豚DNA中也包含了一些描述其更早时期所处世界的段落,相应的基因也存续了下来:那是它的祖先们在陆地上生活的时期,要小心躲避暴龙和异特龙,活得足够久,久到能够生育才行。在那之前,肯定还有一部分DNA描述了更为古老的生存技能,又一次带我们回到了海洋中,那是它的先祖们还是鱼的时期,被鲨鱼甚至是广翅鲎(巨大的海 蝎子)追逐的时代。
历史的沧桑与厚重感.
人为什么要做研究, 是为了看到这些风景吗?
30周年版简介
意识到我已经与《自私的基因》一同走过生命中几乎一半的旅程,这把我彻底吓清醒过来,真不知这是件好事还是坏事。这么多年了,我又出版了七本书。每一本书问世时,出版社总派我四处做宣传。读者们以令人受宠若惊的热情回应我的每一本书。他们礼貌地鼓掌,提出一些有智慧的问题,然后排队购书。但他们让我签名的书却是《自私的基因》。这也许有点儿夸张了,有一些读者还是买新书的。而我妻子安慰我说,那些人只是刚刚发现一个新作者,他们会很自然地会去寻找作者的第一本书,阅读《自私的基因》,当然,之后他们肯定会一直读到最新一本书,那才是作者最喜欢的“孩子”。
1975年时,经过我的朋友德斯蒙德·莫里斯(Desmond Morris)的帮助,我将完稿的部分章节交给伦敦出版界的老前辈汤姆·马希勒(TomMaschler)。我们在乔纳森·凯普(Jonathan Cape)出版社中他的房间里讨论。他表示喜欢这本书,但不喜欢标题。“自私,”他说,“是一个消极的单词。为什么不叫它‘不朽的基因’呢?不朽是一个积极的词,基因信息的不朽是这本书的主题思想,而‘不朽的基因’与‘自私的基因’听起来几乎一样耐人寻味。”(我现在觉得,我们俩都没意识到《自私的基因》刚好呼应了王尔德的《自私的巨人》。)但我现在觉得马希勒也许是对的。许多批评家——特别是那些哗众取宠的批评家(我发现他们一般都有哲学背景)——喜欢不读书而只读标题。也许这个 方法足以适用于《兔子本杰明的故事》或者《罗马帝国兴衰史》,但我可以不假思索地说,“自私的基因”标题本身,如果不包含书上大字的脚注,会使人对内容产生一种不恰当的印象。如今,有一个美国出版社无论如何都坚持要求加一个副标题。
解释这个标题最好的方法是标记重点。如果重点在“自私”,你便会以为这本书在讨论人的私心,但是本书却将更多的重心放在讨论利他主义上。这个标题里需要着重强调的词应该是“基因”。让我来解释一下原因。达尔文主义中一直有一个中心辩论议题:自然选择的单位究竟是什么?自然选择的结果究竟是哪一种实体的生存或者灭亡?这个选择的单位多少会变得“自私”。利他主义则在另一个层次才被看重。自然选择是否在种群中选择?如果是这样的话,我们应该能看到个体生物因为“种群的利益”而表现出利他行为。它们将降低生育率以控制种群数量,或者限制其捕猎行为以保持未来种群的猎物储备。正是这个广泛流传的对达尔文主义的误解,给了我写作本书的最初动机。
利己与利它.
最小单位.
前提假设如此.
让我来重复并扩展一下对书名中“自私”一词的解释。这里的关键问题是:生命中哪一层次是自然选择的单位,有着不可避免的“自私”属性?自私的种属?自私的群体?自私的生物体?自私的生态系统?我们可以争论这些层次中大多数单位的自私性,它们还都曾被一些作者全盘肯定为自然选择的单位。但这都是错误的。如果一定要把达尔文主义简单概括为“自私的某物”,这本书以令人信服的理由层层推理得出,这个“某物”只能是基因。这是我对标题的解释,无论你是否愿意相信推理本身。
我希望这可以澄清那些更严重的误解。尽管如此,我自己也在同样的地方发现了自己犯过的错误。这从第1章中的一句话可以看出来:“我们可以尝试传授慷慨和利他,因为我们生而自私。”传授慷慨与利他并没有错误,但“生而自私”则可能产生误解。我直到1978年才开始想清楚“载体”(一般是生物体)和其中的复制因子(实际上便是基因,第二版中新加入的第13章解释了这个问题)之间的区别。请你在脑海里删除类似这句话的错误句子,并在字里行间补充正确的含义。
再往下就是分子原子碱基对了. 基因算是能研究的最小单位了.
基因是 “自私” 的. 生物个体是基因的载体, 它的行为由基因操控, 目的是尽可能把基因传递下去.
不同基因可能会有不同的目标策略, 由此在生物个体上的表现形式也不尽相同.
人说的性之善恶没有绝对之分, 某种程度上都是基因的表现形式.
“合作的基因”是《自私的基因》另一个好的替代书名。虽然这听起来自相矛盾,但这本书主要的一部分便是讨论自私基因的合作形式。需要强调的是,基因组们并不需要以牺牲同伴或者他人的代价来换取自身的繁荣发展。相反,每一个基因在基因库里——生物体以性繁殖洗牌获得的基因组合,以其他基因为背景,追求着自身利益。其他基因是每一个基因生存大环境中的一部分,正如天气、捕食者与猎物、植被与土壤细菌都是环境的一部分。从每个基因的角度上看,背景基因可以与之共享生物体,相伴走过世代旅程。短期看,背景基因指的是基因组中的其他基因。但从长期看,背景基因则是种群基因库内的其他基因。因此,自然选择将基因视作相互兼容——几乎等同于合作——的团体,自然选择偏爱那些共同存在的基因。然而,无论在什么时候,这种合作基因的演化违反了自私基因的根本原则。第5章以桨手的比喻来讲述这个理论,第13章则更进一步讨论了这个问题。
对基因的拟人化处理
《自私的基因》一直因为将基因拟人化而受到批评,这一点也需要解释一下(如果不需要道歉的话)。我采用了两个层次的拟人:基因与生物体。基因的拟人真不应该是个问题,因为任何有头脑的人都不会认为DNA分子会有一个有意识的人格,任何理智的读者也不会将这种妄想归罪于作者的写作方式。有一次我听到伟大的分子生物学家雅克·莫诺(Jacques Monod)讲述科学中的创造力时,着实心动。我已经忘记了他的用词,但他大概的说法是:当他考虑一个化学问题时,他会问自己,如果我是个电子,我会怎么做?彼得·阿特金斯(Peter Atkins)在其优秀的著作《重临创世》(Creation Revisited)中,在探讨光束通过高折射率介质速度减慢后的折射时,也采取了一个类似的拟人:光束好像想要将其到达终点的时间最小化。在阿特金斯的想象中,这如同海滩边的救生员冲过去拯救一个落水者一样。他是否需要按直线靠近落水者?不需要,因为他跑步比游泳速度更快,在行程中增加陆地行走的比例会更为明智。他是否应该直接跑到海滩边正对着目标的点,来最小化其游泳时间?这个想法好一些,但依然不是最佳方案。通过计算(如果救生员有时间来做这个事情),我们可以找到救生员的最佳行进角度、奔跑距离和不可避免的游泳距离间的最佳组合。阿特金斯总结道:
这正是光线通过密度较大介质时的行为。但光线怎么能在进入之前就已经知道哪一个是最短的行程?它又为什么要在乎这个?
他受量子理论的启发,对这些问题给出了一个绝佳的解释。这类拟人化的比喻并不只是一种有趣的叙述方式,它还可以帮助职业科学家在雾里看花中,排除错误,找到正确的答案。达尔文主义在利他主义和自私、合作与报复上的计算便是这么一个例子,科学家们很容易推算出错误的答案。但我们经常在最后发现,适当地、小心谨慎地将基因拟人化处理,是将达尔文理论学者从泥沼中拯救出来的最短路径。在本书四大英雄之一的汉密尔顿先驱经验的鼓励下,我自己也尝试着如此谨慎处理拟人化。汉密尔顿在1972年(也是我开始写作《自私的基因》的那一年)的论文里写道:如果一个基因可以使其复制品聚集起来,形成基因库中一个不断增加的部分,它便会得到自然选择的青睐。我们关注的那些基因会对其携带者的社会行为产生影响。为了让我们的论证更加生动有趣,让我们先试着暂时赋予这些基因以智慧和自由选择的意志。想象一下,一个基因正在考虑问题:如何增加其拷贝。再想象一下它可以有所选择……
方便理解.
基因让你心甘情愿去死
将生物体拟人化则更加麻烦。这是因为生物体不同于基因,它们拥有大脑,因此也可能真正拥有自私与利他之类主观意识的想法,让我们可以辨识出来。如果本书叫作“自私的狮子”可能会真的迷惑读者,而“自私的基因”不应有这种问题。就像有人可以把自己想象为光束,聪明地选择通过级联透镜与棱镜的最佳路径,或者将自己想象为基因,选择传递千秋万代的最佳路径,我们也可以假定一只狮子计算着其基因长期生存的最佳行为策略。汉密尔顿带给生物学的第一份礼物是其准确的数学计算,这可以算出一只真正的达尔文主义的生物——比如狮子——决定将其基因长期生存的概率最大化时,所应采取的策略。
在本书中,我采用了生物体和基因的两个层次,用非正式、口语化的语言来描述这种计算。在第150页里,我们迅速从一个层次转向另一个层次:
我们已经考虑过在什么条件下母亲让小个子死掉事实上是合算的。如果单凭直觉判断,我们大概总是认为小个子本身是会挣扎到最后一刻的,但这种推断在理论上未必能站得住脚。一旦小个子瘦弱得使其预期寿命缩短到它从同样数量的亲代投资中获得的利益还不到其他幼儿的一半时,它就该体面而心甘情愿地死去。这样,它的基因反而能够获益。
这是个体层次的自我审视。这里的假设不是小个子做出让自己快乐和感觉良好的选择,而是达尔文世界的个体生物会做出的“如果……那么……”的估算,以得出对其基因最有利的选择。
这个段落还在继续明确地迅速转化至基因层面的拟人化:就是说,一个基因发出了这样的指令:“喂,如果你个子比你的骨肉兄弟瘦小得多的话,那你不必死捱活撑,干脆死了吧!”
这个基因在基因库中将取得成功,因为它在小个子体内活下去的机会本来就很小,而它却有50%的机会存在于得救的每个兄弟姐妹体内。
小个子的生命航程中有一个有去无回的临界点。在达到这一临界点之前,它应当争取活下去,但到了临界点之后,它应停止挣扎,宁可让自己被骨肉兄弟或父母吃掉。
小狮子如果继续挣扎求生作为个体生存下去, 它的亲属 (和它有相同基因的其它小狮子) 的生存机会会受到损害, 并且这个损害超过了它自己获得的收益, 所以基因操控它心甘情愿去死.
人也有这样的行为, 天性如此啊.
这个视角很有启发.

这个叫配得感吗.
(这本书)非常引人入胜,但有时我希望我没有读过它……一方面,我惊叹于道金斯极为清晰且有根据地看清如此复杂的过程……但同时,我还要责怪《自私的基因》使我在之后的10多年里,不得不与抑郁症进行长期较量……我不再对生命灵魂的认识感到确定,并尝试寻找更深层次的东西——试着去相信,但却不能相信——我发现这本书在字里行间将我所有模糊的想法都一扫而光,而且阻止这些想法重新凝聚于我的脑海中。几年前,这造成了我个人生活中的一次严重危机。
我之前也描述过一些读者产生的类似反应:
我第一本书的一个外国出版商坦言:阅读这本书后,他失眠了3天,被书中传达的冷酷无情的信息深深困扰。另外一些人则问我每天早上如何能离开床铺。一个偏远乡村的教师写信责备我,因为一个学生读完书后含泪找到他,说这本书使她的生命变得空虚而无意义。他建议她不要把这本书给她的任何朋友看,因为他害怕这本书会使他们产生相同的虚无主义思想与悲观情绪。(摘自《解析彩虹》)如果这些故事是真的,任何良好愿望都无法将其掩盖。这是我要说的第一件事,但我要说的第二件事也一样重要。
我在书里接着写道:想必宇宙的最终命运确实没有意义,但无论如何,我们真有必要将我们生命的希望寄托在宇宙的最终命运上吗?当然不需要,只要我们足够明智。我们的生命被其他更密切、更温暖的人类理想与感觉控制。指责科学剥夺了生命中赖以生存的温暖,是多么荒谬的错误啊,这与我本人及其他科学家的感觉截然相反。我几乎都要对这些大错特错的怀疑绝望了。
这是什么脑回路?
我好像不是很能理解为什么读了本书就抑郁了.


这是啥, 我执吗.
另一些批评家则表现出类似“因坏消息到来而迁怒信使”的趋势,他们从《自私的基因》中看到不合心意的社会、政治或经济上的推论,因此反对此书。在1979年撒切尔夫人刚获得其第一次选举胜利后不久,我的朋友史蒂文·罗斯(Steven Rose)在给《新科学家》的文章中写道:
我不是说上奇公司(Saatchi&Saatchi)曾组织一批社会生物学家来撰写撒切尔夫人的演讲稿,更不是指一些牛津与苏塞克斯的君子已经开始庆幸终于可以从实际情况解读自私基因这等简单事实,尽管他们一直拼命想要这么告诉我们。这个流行理论与政治事件的巧合要更乱七八糟得多。不过我相信,20世纪70年代末期此书写成时,历史潮流转向了右翼,从法律与秩序转向货币主义与(更为矛盾的)对中央集权的抨击。之后这个转向才成为科学潮流,如果进化理论从类群选择转向亲属选择也能算的话。这个科学潮流变换将被看作推动撒切尔夫人派与其僵化的、19世纪时竞争与排外的人性概念执掌大权的社会潮流的一部分。
“苏塞克斯的君子”指的是不久前去世的约翰·梅纳德·史密斯,史蒂文·罗斯和我都同样欣赏他。史密斯在回复《新科学家》的信中以其典型口吻说:“我们还能怎么做?篡改公式吗?”《自私的基因》传递的一个重要消息(史密斯的文章标题“魔鬼的牧师”更强调了这一信息)是:我们不能把我们的价值观从达尔文主义中推导而来,除非它带着一个消极的信号。我们的大脑已经进化到一个程度,使我们得以背叛自身的自私基因。这种行为的一个明显现象便是我们使用的避孕方式。同样的原理可以也应该作用于更广的范围。
自私也不能就等于同于人性本恶呀.
不是还有利它行为呢么.
第2版前言
两种视角: 基因与个体
《自私的基因》出版十几年来,书中的主要信息已经成为教科书的正统内容。这其实很矛盾,虽然看起来并不明显,但它并不是那一类作品:出版时因其革命性颠覆而备受指责,而后逐渐稳定获得皈依者,最后被认为无比正统,使人不解最初争议从何而来。《自私的基因》恰与之相反。一开始它得到好评无数,并不被视为富有争议的书。直到数年后,它的争议才逐渐形成。而现在,它被广泛认为是极端的激进作品。但同样在这些年里,当此书极端主义的名声逐渐升级时,它实际的内容则显得越来越不极端,越来越接近通用常识。
自私基因的理论也是达尔文的理论,只是以一种达尔文并未选择的方式来表述。而我也愿意认为,达尔文如果九泉之下有知,也会立刻认识到这种方式的合适性,并为此高兴。这事实上是正统的新达尔文主义的一种逻辑推论,仅仅是以一个新形象展现出来。它并不关注个体生物,而是从基因的视角看待自然界。这是一种不同的观察方式,而不是一种不同的理论。在《延伸的表型》的开篇,我曾用内克尔立方体的比喻来解释这一点。这是一个二维的纸上墨印图案,但它在观察者眼中却是一个透明的三维立方体。盯着它看上几秒钟,它会变为朝向另一个方向。继续盯着它看,它则会变成原来的立方体。这两个立方体都与视网膜中的那个二维图形同等兼容,于是大脑很乐意在两者间轮流更换。任何一个图形都不比另一个更为正确。我所要说的,便是自然选择有两种观察的方式,可以从基因的角度,也可以从个体生物的角度来观察。如果你恰当地理解两者,它们便是等同的,是同一真理的两种看法。你可以从一者转化到另一者,它依然是相同的新达尔文主义。
我现在觉得这个比喻太过于小心翼翼了。一个科学家最重要的贡献通常并不是提出一个新理论,或是揭示一个新现象,而是于旧理论和旧现象中发现观察的新方法。内克尔立方体的比喻有误导性,因为它表示两种观察方法的好处是相同的。确切地说,这个比喻还是部分正确的:“角度”和理论不一样,不可以通过实验去验证。我们无法采用熟悉的证明或证伪准则。但在最理想的情况下,视角的改变可以达到比一个理论更崇高的地位。它可以引领整个思想潮流,促使许多激动人心与可验证的理论产生,使之前无法想象的事实暴露无遗。内克尔立方体的比喻完全忽略了这点,它只抓住了视角上改变这一点,却无法公正评价其价值。我们要谈的并不是一个视角的转变,而是在极端条件下的彻底变身。
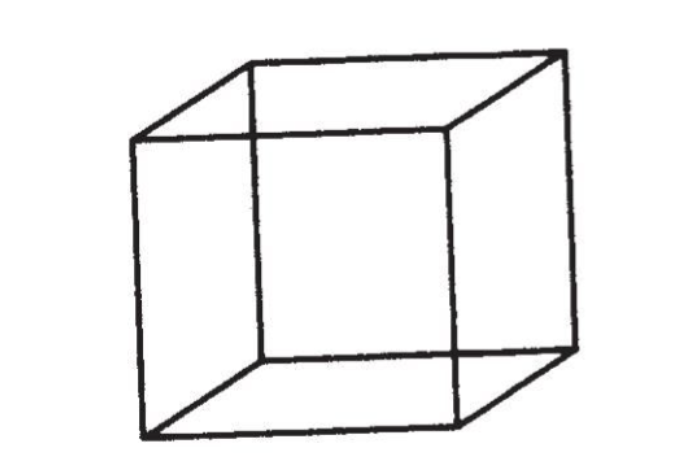
个人感觉从基因的角度其实更好, 能解释地更细致更根本.
将那些迄今只在专业文献中存在的思想仔细阐述出来,实在是一项困难的艺术。它需要语言上有洞察力的新方法与浅显易懂的比喻。如果你可以强调语言和比喻的新颖,你最终能得到一种新思维。而新思维本身便是对科学的一种原创贡献,正如我之前讨论的那般。爱因斯坦本人便是一位出色的科学普及者。我经常觉得他那些生动的比喻并不只帮助了我们这些读者。它们难道没有为这位极富创造力的天才的思维火花增添燃料吗?
“好人终有好报”的标题出自1985年我参与的BBC电视节目《地平线》。这是一部50分钟的纪录片,由杰里米·泰勒(Jeremy Taylor)制作,以博弈论探讨进化中的合作。这部纪录片的制作,连同另一部来自相同制作人的《盲眼钟表匠》,使我对其职业产生新的敬意。《地平线》的制作人们竭尽全力使自己成为该题目的高级专家(他们的一些节目在美国也能看到,通常以《新星》的名目重新包装)。第12章不仅从中收获了章名,我、泰勒和《地平线》制作组的紧密合作也使第12章的写作获益不少。对此我深表感激。
最近我了解到一个我不敢苟同的事实:一些有影响力的科学家习惯在他们并未参与的作品中署上自己的名字。显然,一些资深科学家要求在作品中署名,只是因为他们贡献了实验场所、科研资金和对文章编辑提出了修改意见。就我所知,他们在学界的声誉可能完全建立于其学生和同事的工作成果之上!我不知道如何与这种不诚实的行为抗争,也许期刊编辑应该要求每一名作者签字表明其贡献。但这不过闲谈而已,我提起这个话题是为了做一个对比。海伦娜·克罗宁(Helena Cronin)对这本书的每一行,甚至每一个字都做了力所能及的改进,却坚持拒绝了成为书中新增部分的共同作者的请求。我对她感激不尽,并对我的感谢必须止于此表示歉意。我还要感谢马克·里德利(Mark Ridley)、玛丽安·道金斯(Marian Dawkins)和艾伦·格拉芬对本书的建议和对一些章节的建设性批评意见。另外还要感谢牛津大学出版社的托马斯·韦伯斯特(Thomas Webster)、希拉里·麦格林(Hilary McGlynn)和其他欣然容忍了我的奇思妙想和拖延的同事。
哈哈哈艹这不是常规操作吗.
只能说有这种类型基因的人能更好地生存下去.
序言
例如,如果(按道金斯的论证)欺骗行为是动物间交往的基本活动的话,动物就一定存在对欺骗行为的强烈的选择性,而动物也转而必须选择一定程度的自我欺骗,使某些行为和动机变成无意识的,从而不致因极细微的自觉迹象,让正在进行的欺骗行为败露。因此,认为自然选择有利于更准确地反映了世界形象的神经系统这种传统观点,肯定是一种关于智力进化的非常幼稚的观点。
神经系统也会欺骗自己的宿主.
近年来,人们在社会学说方面取得了重大进展,由此引发了一股小小的逆流。例如,有人断言,近年来社会学说方面的这种进展,事实上是为了阻止社会进步的周期性阴谋的一部分,这种进步在遗传上似乎是不可能的。还有,把一些相似而又不堪一驳的观点罗列在一起,使人产生这样一种印象,即达尔文的社会学说,其政治含义是反动的。这种说法同事实情况大相径庭。费希尔和汉密尔顿首次清楚地证明了遗传上性别的均等性。从社会性昆虫得到的理论和大量数据表明,亲代没有主宰其子代的固有趋势(反之亦然)。而且亲代投资和雌性选择的概念,为观察性别差异奠定了客观而公正的基础,这是一个相当大的进展,超越了一般把妇女的力量和权利归结于毫无实际意义的生物学上的特性这一泥潭所做的努力。总之,达尔文主义的社会学说使我们窥见了社会关系中基本的对称性和逻辑性,在我们有了更充分的理解之后,我们的政治见解将会重新获得活力,并对心理学的科学研究提供理论上的支柱。在这一过程中,我们也必将对苦难的众多根源有更深刻的理解。
这什么勾巴翻译.
前言
读者不妨把本书当作科学幻想小说来阅读。笔者构思行文着意于引人深思,唤起遐想。然而,本书绝非杜撰之作。它不是幻想,而是科学。“事实比想象更离奇”,暂不论这句话是否有老生常谈之嫌,它却确切地表达了笔者对客观事实的印象。我们都是生存机器——作为运载工具的机器人,其程序是盲目编制的,为的是永久保存所谓基因这种禀性自私的因子。这一事实直至今天仍使我惊叹不已。我对其中的道理虽已领略多年,但它始终使我感到有点难以置信。我的愿望之一是能够凭此使读者惊叹不已。
第1章 为什么会有人呢?
我的目的是研究自私行为和利他行为在生物学上的意义。除了学术意义,这个主题对人类的重要性也显而易见。它关乎我们人类生活的各个方面,我们的爱与憎、斗争与合作、馈赠与盗窃、贪婪与慷慨。这些本来是洛伦茨(Lorenz)的《论进犯行为》(On Aggression)、阿德里(Ardrey)的《社会契约》(The Social Contract)和埃布埃尔——埃尔布菲尔特(Eibl-Eibesfeldt)的《爱与憎》(Love and Hate)探讨的主题。这3本书的问题在于它们的作者铸下了大错。他们犯错是因为他们误解了进化论。他们错误地假定进化的关键在于物种(或者种群)的利益,而不是个体(或者基因)的利益。可笑的是,阿什利·蒙塔古(Ashley Montagu)批评洛伦茨,说他是“(相信)‘大自然是残酷无情的’的19世纪思想家的‘嫡系’……”。在我看来,洛伦茨和蒙塔古是半斤八两,二人都拒斥丁尼生这个著名短语的含义。与二人不同,我认为这句话极好地概括了我们对自然选择(理论)的现代理解。
别笑了戈门, dna 之下还有 rna 蛋白质有碱基对氨基酸有分子原子中子质子电子夸克量子.
你说以后谁出个书叫 “自私的量子” / “自私的道” 来笑话你你乐意吗.
上述有关利他和自私的定义是指行为上的,而不是指主观意识上的,弄清这一点至关重要。在这里我的旨趣不在动机的心理学方面,我不准备去论证人们在做出利他行为时,是否“真的”私下或下意识地抱有自私的动机。他们或许是,或许不是,也许我们永远也不可能知道。但无论怎样,这些都不是本书所要探讨的内容。我的定义只涉及行为的效果,是降低还是提高这个假定的利他主义者生存的可能性,以及这个假定的受益者生存的可能性。
对于刚提出的上述争论,“个体选择”论者可以不假思索地这样回答:几乎可以肯定,即使在利他主义者的群体中也有少数持不同意见者拒绝做出任何牺牲。假如有一个自私的叛逆者准备利用其他成员的利他主义,按照定义,它比其他成员更可能生存下来并繁殖后代。这些后代都有继承其自私特性的倾向。这样的自然选择经过几代之后,利他性的群体将会被自私的个体淹没,就不能同自私性的群体分辨开来了。我们姑且假定开始时存在无叛逆者的纯粹利他性群体,尽管这不大可能,但很难看出又有什么东西能够阻止自私的个体从邻近的自私群体中移居过来,然后由于相互通婚,玷污了利他性群体的纯洁性。
个体选择论者也会承认群体确实会消亡,也承认一个群体是否会灭绝可能受该群体中个体行为的影响。他们甚至可能承认,只要一个群体中的个体具有远见卓识,就会懂得克制自私贪婪,到头来成为它们的最大利益所在,从而避免整个群体的毁灭。但同个体竞争中那种短兵相接、速战速决的搏斗相比,群体灭绝是一个缓慢的过程,甚至在一个群体缓慢地、不可抗拒地衰亡时,该群体中的一些自私的个体,在损害利他主义者的情况下,仍可获得短期的繁荣。
类群选择, 利己与利他行为, 个体对其它群体成员的利他本质上也可以看成是基因的利己.
洛伦茨在《论进犯行为》一书中讲到进犯行为在物种保存方面的功能时,认为功能之一是确保只有最适合的个体才有繁殖的权利。这是个典型的循环证明。但这里我要说明的一点是,类群选择的观点竟如此根深蒂固,以至于洛伦茨像《纳费尔德生物学教师指南》的作者一样,显然不曾认识到,他的说法同正统的达尔文学说是相抵触的。
雄竞雌竞吗.
尽管类群选择的理论在今天已得不到那些了解进化论的专业生物学家多大的支持,但它仍具有巨大的直观感召力。历届动物学学生在进入大学之后,都惊奇地发现这不是一种正统的观点。这不该责怪他们,因为在为英国高级生物学教师编写的《纳费尔德生物学教师指南》一书中,我们可以找到下面这句话:“在高级动物中,为了确保本物种的生存,会出现个体的自杀行为。”这本指南的不知名作者幸而根本没有意识到他提出了一个有争议的问题。在这方面这位作者和诺贝尔奖得主洛伦茨所见略同。洛伦茨在《论进犯行为》一书中讲到进犯行为在物种保存方面的功能时,认为功能之一是确保只有最适合的个体才有繁殖的权利。这是个典型的循环证明。但这里我要说明的一点是,类群选择的观点竟如此根深蒂固,以至于洛伦茨像《纳费尔德生物学教师指南》的作者一样,显然不曾认识到,他的说法同正统的达尔文学说是相抵触的。最近我在英国广播公司电视节目中听到一个有关澳大利亚蜘蛛的报道。节目中提到一个同样性质的、听来使人忍俊不禁的例子,如没有这个例子,那倒是一档相当精彩的节目。主持这一节目的“专家”评论说,大部分蜘蛛幼虫最后为其他物种所吞食。然后她继续说:“这也许就是它们生存的真正目的,因为要保存它们的物种,只需要少数几个个体生存就行。”阿德里在《社会契约》中用类群选择的理论解释整个社会的秩序。他明确地认为,人类是从动物这条正路偏离出来的一个物种。阿德里至少是个用功的人,他决定和正统的理论唱反调是经过充分论证的。为此,他应受到赞扬。
哦这是在在批判类群选择理论吗, 我以为说什么呢.
这意思不就是类群选择不够根本要从基因角度解释, 有话不能直说吗.
同一物种中的成员同其他物种的成员相比,前者更应得到道义上的特殊考虑,这种情感既古老又根深蒂固。非战时杀人被认为是日常犯罪中最严重的罪行。受到我们文明更加严厉的谴责的唯一一件事是吃人(即使是吃死人),然而我们却津津有味地吃其他物种的成员。我们当中许多人在看到那些哪怕是人类最可怕的罪犯被执行死刑时,也觉得惨不忍睹,但我们却兴高采烈地鼓励射杀那些相当温顺的供观赏的动物。我们确实是以屠杀其他无害物种的成员作为寻欢作乐的手段的。一个人类的胎儿,所具有的人类感情丝毫不比一个阿米巴多,但它所享受的尊严和得到的法律保护却远远超过一只成年的黑猩猩。黑猩猩有感情,有思维,而且最近的试验证明,黑猩猩甚至能够学会某种形式的人类语言。就因为胎儿和我们同属一个物种,就立刻被赋予相应的特殊权利。我不知道能否将“物种主义”的道德[赖德(Richard Ryder)用语]置于一个比“种族主义”更合理的地位上,但我知道,这种“物种主义”在进化生物学上是毫无正当依据的。
第2章 复制因子
“原始汤”的形成想来必然是过程与此类似的结果。生物学家和化学家认为“原始汤”就是大约30亿到40亿年前的海洋。有机物质在某些地方积聚起来,也许在岸边逐渐干燥起来的浮垢上,或者在悬浮的微小水珠中。在受到如太阳紫外线之类的能量的进一步影响后,它们就结合成大一些的分子。现今,大的有机分子存在的时间不会太长,我们甚至觉察不到它们的存在,它们会很快被细菌或其他生物吞噬或破坏。但细菌以及我们人类都是后来者。所以在那些日子里,有机大分子可以在稠浓的汤中平安无事地自由漂浮。
到了某一时刻,一个非凡的分子偶然形成——我们称之为复制因子(replicator)。它并不见得是那些分子当中最大或最复杂的,但它具有一种特殊的性质——能够复制自己。看起来这种偶然性非常之小。的确是这样,发生这种偶然情况的可能性是微乎其微的。在一个人的一生中,实际上可以把这种千年难得一遇的情况视为不可能,这就是为什么你买的足球彩票永远不会中头等奖的道理。但是我们人类在估计什么可能或什么不可能发生的时候,不习惯于将其放在几亿年这样长久的时间内去考虑。如果你在一亿年中每星期都购买一次彩票,说不定你会中上几次头等奖呢。
事实上,一个能复制自己的分子并不像我们原来想象的那样难得,这种情况只要发生一次就够了。我们可以把复制因子当作模型或样板,把它想象为由一条复杂的链构成的大分子,链本身是由各种类型的起构件作用的分子组成的。在复制因子周围的汤里,这种小小的构件多得是。现在让我们假定每一块构件都具有吸引其同类的亲和力。来自汤里的这种构件一接触到对之有亲和力的复制因子的另一部分,就往往附着在那儿不动了。按照这个方式附着在一起的构件会自动地仿照复制因子本身的序列排列起来。这时我们就不难设想,这些构件逐个地连接起来,形成一条稳定的链,和原来复制因子的形成过程一模一样。这个一层一层逐步堆叠起来的过程可以继续下去,结晶体就是这样形成的。另一方面,两条链也有一分为二的可能,这样就产生了两个复制因子,而每个复制因子还能继续复制自己。
一个更为复杂的可能性是,每块构件对其同类并无亲和力,而对其他的某一类构件却有互相吸引的亲和力。如果情况是这样的,复制因子作为样板并不产生完全相似的拷贝,而是某种“反象”,这种“反象”转过来再产生和原来的正象完全相似的拷贝,对我们来说,不管原来复制的过程是从正到反还是从正到正都无足轻重;但有必要指出,现代的第一个复制因子即DNA分子,它所使用的是从正到反的复制过程。值得注意的是,突然间,一种新的“稳定性”产生了。在以前,汤里很可能并不存在非常大量的某种特殊类型的复杂分子,因为每一个分子都要依赖于那些碰巧产生的结构特别稳定的构件。第一个复制因子一旦诞生了,它必然会迅速地在海洋里到处扩散它的拷贝,直至较小的构件分子日渐稀少,而其他较大的分子也越来越难有机会形成。
但其他条件可能是不相等的。对某一品种的复制因子来说,它具有另外一个甚至更为重要的、为了在种群中传布的特性,这就是复制的速度或“生育力”。如果A型复制因子复制自己的平均速度是每星期一次,而B型复制因子是每小时一次,显而易见,不需多久,A型因子的数量就要相形见绌,即使A型因子的“寿命”再长也无济于事。因此,汤里面的因子很可能出现一种“生育力”变得更强的“进化趋向”。复制因子肯定会选择的第三个特性是复制的准确性。假定X型因子与Y型因子的寿命同样长,复制的速度也一样快,但X型因子平均在每10次复制过程中犯一次错误,而Y型只在每100次复制过程中犯一次错误,那么Y型因子肯定要变得多起来。种群中X型因子这支队伍不但要失去它们因错误而养育出来的“子孙”,还要失去它们所有现存或未来的后代。
使得复制因子存续壮大的因素: 可复制性, 稳定性, 生育力.
自然选择中 "稳定" 的含义
所谓稳定的意思是,那些因子要么本身存在的时间较长,要么能迅速地复制,要么能精确无误地复制。朝着这三种稳定性发展的进化趋向是在下面这个意义上发生的:如果你在两个不同的时间分别从汤中取样,后一次的样品一定含有更大比例的寿命长或生育力强或复制精确性高的品种。生物学家谈到生物的进化时,他所谓的进化实质上就是这个意思,而进化的机制是一样的——自然选择。
从复制因子角度看细胞与个体如何产生
论点的第二个重要环节是竞争。达尔文本人也强调过它的重要性,尽管他那时讲的是动物和植物,不是分子。原始汤是不足以维持无限量的复制因子分子的。其中一个原因是地球的面积有限,但其他一些限制性因素也是非常重要的。在我们的想象当中,那个起着样板或模型作用的复制因子浮游于原始汤之中,周围存在大量复制所必需的小构件分子。但当复制因子变得越来越多时,构件因消耗量大增而供不应求,成为珍贵的资源。不同品种或品系的复制因子必然为了争夺它们而互相搏斗。我们已经研究过是什么因素促进那些条件优越的复制因子的繁殖。我们现在可以看到,条件差一些的品种事实上由于竞争而变得日渐稀少,最后它们中的一些品系难逃绝种的命运。复制因子的各品种之间发生过你死我活的搏斗。它们不知道自己在进行生存斗争,也不会因之而感到烦恼。复制因子在进行这种斗争时不动任何感情,更不用说会引起哪一方的厌恶感了。但从某种意义上来说,它们的确是在进行关乎生死存亡的斗争,因为任何导致产生更高一级稳定性的复制错误,或以新方法削弱对手的稳定性的复制错误,都会自动地延续下来并成倍地增长。改良的过程是积累性的。加强自身的稳定性或削弱对手稳定性的方法变得更巧妙,更富有成效。一些复制因子甚至“发现”了一些方法,通过化学途径分裂对方品种的分子,并利用分裂出来的构件来复制自己。这些原始食肉动物在消灭竞争对手的同时摄取食物。其他的复制因子也许发现了如何用化学方法或把自己裹在一层蛋白质之中来保卫自己。这也许就是第一批生命细胞的成长过程。复制因子的出现不仅仅是为了生存,还是为它们自己制造容器,即赖以生存的运载工具。能够生存下来的复制因子都是那些为自己构造了生存机器以安居其中的复制因子。最原始的生存机器也许仅仅是一层保护衣。后来,新竞争对手陆续出现,它们拥有更优良、更有效的生存机器,因此生存斗争随之逐渐激化。生存机器的体积越来越大,其结构也渐臻复杂。这是一个积累和渐进的过程。
随着时间的推移,复制因子为了保证自己在世界上存在下去而采用的技巧和计谋也逐渐改进,但这种改进有没有止境呢?用以改良的时间是无穷无尽的。1 000年的变化会产生什么样的怪诞的自我保存机器呢?经过40亿年,古代的复制因子又会有怎样的命运呢?它们没有消失,因为它们是掌握生存艺术的老手。但在今日,别以为它们还会浮游于海洋之中。很久以前,它们已经放弃这种自由自在的生活方式了。在今天,它们群集相处,安稳地寄居在庞大的步履蹒跚的“机器人”体内,与外界隔开,通过迂回曲折的间接途径与外部世界联系,并通过遥控操纵外部世界。***它们存在于你和我的躯体内,它们创造了我们,创造了我们的肉体和心灵,而保存它们正是我们存在的终极理由。***这些复制因子源远流长。今天,我们称它们为基因,而我们就是它们的生存机器。
兄弟你这得给那帮抑郁的人背锅了.
复制因子演化下来也没有什么目的和理由, 单纯是那些有利于存续的存续下来了而已.
目的不能脱离于主体存在, 最常见的主体概念就是 “我”.
或许可以说存在这样一个概念, 叫做 “我”.
机器层面, 这是人对自己的认识, 或者是自我意识.
零件层面, 作者将复制因子做了拟人化处理, 赋予了它某种程度上的 “我”, 然后将宏观层面的 “我” 解释为微观层面 “我” 的延续.
但实际上 “我” 的概念是否存在? 在什么层面, 以什么程度存在我们都不得而知.
复制因子会影响 “我” 的行为与表现, 但它不在乎 “我” 是否会将其延续下去.
所以大可不必说机器是零件的奴隶.
第3章 不朽的双螺旋
我们都是同一种复制因子——人们称之为DNA的分子——的生存机器,但生存在世上的方式却大不相同,因而复制因子制造了大量各种各样的生存机器供其利用。猴子是基因在树上生活的保存机器,鱼是基因在水中生活的保存机器,甚至还有一种小虫,是基因在德国啤酒杯草垫中生活的保存机器。DNA的活动方式真是神秘莫测。
我们的DNA寄居在我们体内。它不是集中在体内的某一特定的位置,而是分布在所有细胞之中。人体平均大约由1 000万亿个细胞组成。除某些特殊情况我们可以不予以考虑外,每个细胞都含有该人体的DNA的一套完整拷贝。这一DNA可以被认为是一组有关如何制造一个人体的指令,以核苷酸的A、T、C、G字母表来表示。这种情况就像在一幢巨大的建筑物中,每间房间里都有一个“书橱”,而“书橱”里存放着建筑师建造整幢建筑物的设计图。每个细胞中的这种“书橱”被称为细胞核。人类建筑师的这种设计图共有46“卷”,我们称它们为染色体。在不同的物种中,其数量也不同。染色体在显微镜下是可见的,形状像一条条长线。基因就沿着这些染色体有次序地排列着。但要判断基因之间首尾相接的地方却是困难的,而且事实上甚至可能是无意义的。幸好,本章就要表明,这点同我们的论题关系不大。
我将利用建筑师的设计图这一比喻,把比喻性的语言同专业的语言适当地混在一起来进行叙述。“卷”同染色体这两个词将交替使用,“页”则同基因暂且互换使用,尽管基因相互之间的界线不像书页那样分明,但我们将在很长的篇幅中使用这一比喻。待这一比喻不能解决问题时,我将再引用其他比喻。这里顺便提一下,当然是没有“建筑师”这回事的,DNA指令是由自然选择安排的。
关于现代复制因子,要了解的第一件事就是,它具有高度群居性。生存机器是一种运载工具,它包含的不只是一个基因,而是成千上万个基因。制造人体是一种相互配合的、错综复杂的冒险事业,为了共同的事业,某一个基因做出的贡献和另一个基因做出的贡献几乎是分不开的。一个基因对人体的不同部分会产生许多不同的影响。人体的某一部分会受到许多基因的影响,而任何一个基因所起的作用都依赖于同许多其他基因的相互作用。某些基因充当主基因,控制一组其他基因的活动。用比拟的说法,就是蓝图的任何一页对建筑物的许多不同部分都提供了参考内容,而每一页只有作为和其他许多页相互参照的资料才有意义。
这章讲了很多高中生物的知识啊, 有丝分裂减数分裂交叉互换等位基因…
死去的记忆突然开始攻击我.
以书页比作基因的比喻从这里开始不能再用了。在活页夹中,可以将完整的一页插进去、拿掉或交换,但不足一页的碎片却办不到。然而,基因复合体只是一长串核苷酸字母,并不明显地分为一些各自独立的书页。当然蛋白质链信息的头和尾都有专门的符号,它们同蛋白质信息本身一样,都以同样4个字母表示。这两个符号之间会有制造一种蛋白质的密码指令。如果愿意,我们可以把一个基因理解为头和尾符号之间的核苷酸字母序列和一条蛋白质链的编码。我们用“顺反子”(cistron)这个词来表示这样的单位。有些人将基因和顺反子当作可以相互通用的两个词来使用。但交换却不遵守顺反子之间的界限。不仅顺反子之间可以发生分裂,顺反子内也可发生分裂。就好像建筑师的蓝图是画在46卷自动收报机的纸条上,而不是分开的一页一页的纸上一样。顺反子无固定的长度,只有凭借纸条上的符号,找到信息头和信息尾的符号才能找到前一个顺反子到何处为止,下一个顺反子在何处开始。交换表现为这样的过程:取出相配的父方同母方的纸条,剪下并交换其相配的部分,不论它们上面画的是什么。
遗传单位的平均估计寿命可以很方便地用世代来表示,而世代也可转换为年数。如果我们把整条染色体作为假定的遗传单位,它的生活史也只不过延续一代而已。现在假定8a是你的染色体,是从你父亲那里继承下来的,那么它是在你母亲受孕之前不久,在你父亲的一个睾丸内制造出来的。在此之前,世上从未有过它的存在。这个遗传单位是减数分裂混合过程的产物,即将你祖父和祖母的一些染色体片段撮合在一起。这一遗传单位被置于某一精子个体内,因而它是独特的。这个精子是几百万个精子中的一个,它随这支庞大的微型船船队扬帆航行,驶进你母亲的体内。这个精子(除非你是非同卵的双胞胎)是船队中唯一在你母亲的一个卵子中找到停泊港的一条船。这就是你之所以存在的理由。我们所设想的这一遗传单位,即你的8a染色体,开始同你遗传物质的其他部分一起进行自我复制。现在它以复制品的形式存在于你的全身,但在轮到你生小孩时,就在你制造卵子(或精子)时,这条染色体也随之被破坏。一些片段将同你母亲的8b染色体的一些片段相互交换。在任何一个性细胞中将要产生一条新生的染色体8,它比之前的那条可能“好些”,也可能“坏些”。但除非是一个非常难得的巧合,否则它肯定是与众不同的,是独一无二的。染色体的寿命是一代。
会比喻就多说点.
一个较小的遗传单位,比方说是你染色体8a的1%那么长,它的寿命有多长呢?这个遗传单位也是来自你父亲的,但很可能原来不是在他体内装配的。根据前面的推理,99%的可能性是他从父亲或母亲那里完整无缺地接收过来的。现在我们就假设遗传单位是从他的母亲,也就是你的祖母那里接收来的。同样有99%的可能性她也是从她的父亲或母亲那里完整无缺地接收来的。如果我们追根寻迹地查考一个遗传小单位的祖先,我们最终会找到它的最初创造者。在某一个阶段,这一遗传单位肯定是在你的一个祖先的睾丸或卵巢内首次创造出来的。
让我再重复讲一遍我用的“创造”这个词所包含的颇为特殊的意义。我们设想的那些构成遗传单位的较小亚单位可能很久以前就已存在了。我们讲遗传单位是在某一特定时刻创造的,意思只是说,构成遗传单位的那种亚单位的特殊排列方式在这一时刻之前不存在。也许这一创造的时间相当近,例如就在你祖父或祖母体内发生。但如果我们设想的是一个非常小的遗传单位,它就可能是由一个非常遥远的祖先第一次装配的,它也许是人类之前的一个类人猿。而且在你体内的遗传小单位今后同样也可以延续很久,完整无缺地一代接一代地传递下去。
遗传单位越小,同另外一个个体共有的可能性,即以拷贝的形式在世上出现许多次的可能性就越大。
基因颗粒性的另一个方面是,它不会衰老,即使是活了100万年的基因也不会比它仅活了100年的同伴更有可能死去。它一代一代地从一个个体转到另一个个体,用它自己的方式操纵着一个又一个的个体,达成自己的目的;它在一代接一代的个体陷入衰老死亡之前抛弃这些将要死亡的个体。
就一个基因而言,它的许多等位基因是它不共戴天的竞争者,但其余的基因只是它的环境的一个组成部分,就如温度、食物、捕食者或伙伴是它的环境一样。
我们已经提出了这样的问题,即哪些是“好的”基因最普遍的特性。我们认为“自私”是其中之一。但成功基因所具有的另一个普遍特性是,它们通常把它们的生存机器的死亡至少推迟至生殖之后。毫无疑问,你有些堂兄弟或伯祖父是早年夭折的,但你的直系祖先中没有一个是幼年夭折的。祖先是不会在年幼时就丧生的。
促使其个体死亡的基因被称为致死基因。半致死基因具有某种使个体衰弱的作用,这种作用增加了由于其他因素而死亡的可能性。任何基因都在生命的某一特定阶段对个体施加其最大的影响,致死和半致死基因也不例外。大部分基因是在生命的胚胎阶段产生作用的,另有一些是在童年、青年、中年,还有一些则是在老年。请思考一下这样一个事实:一条毛虫和由它变成的蝴蝶具有完全相同的一组基因。很明显,致死基因往往被从基因库中清除掉了。但同样明显的是,基因库中的晚期活动的致死基因要比早期活动的致死基因稳定得多。假如一个年纪较大的个体有足够的时间,至少进行过若干次生殖之后致死基因的作用才表现出来,那么这一致死基因在基因库中仍旧是成功的。例如,使老年个体致癌的基因可以遗传给无数的后代,因为这些个体在患癌之前就已生殖,而另一方面,使青年个体致癌的基因就不会遗传给众多的后代,使幼儿患致死癌症的基因就不会遗传给任何后代。根据这一理论,年老体衰只是基因库中晚期活动致死基因同半致死基因的一种积累的副产品。这些晚期活动的致死和半致死基因之所以有机会穿过了自然选择的网,仅仅是因为它们是在晚期活动的。
为什么会有有性生殖
我一笔带过的另一个假设,即存在有性生殖和交换,更加难以解释清楚。交换并不总是一定要发生,雄果蝇就不会发生交换,雌果蝇体内也有一种具有压抑交换作用的基因。假定我们要饲养一个果蝇种群,而这类基因在该种群中普遍存在的话,“染色体库”中的染色体就会成为不可分割的自然选择基本单位。其实,如果我们遵循我们的定义进行逻辑推理直到得出结论的话,就不得不把整条染色体视作一个“基因”。
还有,性的替代方式是存在的。雌蚜虫能产出无父的、活的雌性后代。每个这样的后代都具有它母亲的全部基因(顺便提一下,母亲“子宫”内的胎儿的子宫内甚至可能有一个更小的胎儿。因此,一只雌蚜虫可以同时生一个女儿和一个外孙女,它们相当于这只雌蚜虫的双胞胎)。许多植物的繁殖以营养体繁殖的方式进行,形成吸根。这种情况我们宁可称其为生长,也不叫它生殖。然而你如果仔细考虑一下,生长同无性生殖之间几乎无任何区别,因为二者都是细胞简单的有丝分裂。有时以营养体繁殖的方式生长出来的植物同“母体”分离开来,在其他情况下,如以榆树为例,连接根出条可以保持完整无损。事实上,整片榆树林可以被看作一个单一的个体。
因此,现在的问题是:如果蚜虫和榆树不进行有性生殖,为什么我们要费这样大的周折把我们的基因同其他人的基因混合起来才能生育一个婴儿呢?看上去这样做的确有点古怪。性活动,这种把简单的复制变得反常的行为,当初为什么要出现呢?性到底有什么益处?
…
从整个个体的角度来看,“有效性”无关紧要。有性生殖与无性生殖相对,可以被视作单基因控制下的一种特性,就同蓝眼和棕眼一样。一个“负责”有性生殖的基因为了它自私的目的而操纵其他全部基因,负责交换的基因也是如此。甚至有一种叫作突变子的基因,它们操纵其他基因中的拷贝错误率。按照定义,拷贝错误对错误地拷贝出来的基因是不利的,但如果这种拷贝错误对诱致这种错误的自私的突变基因有利的话,那么这种突变基因就会在基因库里扩散开。同样,如果交换对负责交换的基因有好处,这就是存在交换现象的充分理由;如果同无性生殖相对的有性生殖有利于负责有性生殖的基因,这也就是存在有性生殖现象的充分理由。有性生殖对个体的其余基因是否有好处,比较而言也就无关紧要了。从自私基因的观点来看,性活动也就不那么难以解释了。
第4章 基因机器
大脑对生存机器做出实际贡献的主要方式在于控制和协调肌肉的收缩。为了达到这个目的,它们需要有通向各个肌肉的导线,也就是运动神经。但对基因的有效保存来说,只有在肌肉的收缩时间和外界事件发生的时间具有某种关系时才能实现。上下颌肌肉的收缩必须等到嘴巴里有值得咀嚼的东西时才有实际意义。同样,腿部肌肉要在出现值得奔跑过去或必须躲避的东西时,按跑步模式收缩才有实际意义。正因如此,自然选择有利于这样一些动物,它们具备感觉器官,能将外界发生的各种形式的有形事件转化为神经元的脉冲码。大脑通过被称为“感觉神经”的导线与感觉器官——眼、耳、味蕾等一一相连。感觉系统如何发生作用尤其使人感到费解,因为它们识别影像的高度复杂的技巧远胜于最优良、最昂贵的人造机器。如果不是这样的话,打字员都要成为冗员,因为他们的工作完全可以由识别言语或字迹的机器代劳。在未来的数十年中,打字员还是不会失业的。
从前某个时候,感觉器官可能在某种程度上直接与肌肉联系,实际上,今日的海葵还未完全脱离这种状态,因为对它们的生活方式来说,这样的联系是有效的。但为了在各种外界事件发生的时间与肌肉收缩的时间之间建立起更复杂的间接联系,就需要有大脑的某种功能作为媒介。在进化过程中,一个显著的进展是记忆力的“发明”。借助这种记忆力,肌肉收缩的定时不仅受不久以前而且也受很久以前的种种事件的影响。记忆装置,或贮存器,也是数字计算机的主要部件。计算机的记忆装置比我们的记忆力更为可靠,但它们的容量较小,而且在信息检索的技巧方面远逊于我们的记忆力。
打字员是什么?
计算机下棋的水平如今还未能达到象棋大师那样的水平,但它足以与一个优秀的业余棋手媲美。更准确的说法是,计算机的程序足以与一个优秀的业余棋手媲美,因为程序本身对使用具体哪一台计算机来表演其技巧是从不苛求的。那么,程序员的任务是什么呢?第一,他肯定不像一个演木偶戏的牵线人那样每时每刻操纵计算机(这是作弊行为)。他编好程序,把它输入计算机内,接着计算机便独立操作:没有人进行干预,除了让对手把他的一着输入机内。程序员是否预先估计到一切可能出现的棋步,从而编好一份长长的清单,列出针对每一种情况的妙着?当然不是这样。因为在棋局中,可能出现的棋步多如恒河沙数,就是到了世界末日也编不出一份完备的清单来。也是出于同样的理由,我们不可能为计算机编制这样一份程序,使它能在“电脑”里事先走一次所有可能出现的棋步,以及所有可能的应着,以寻求克敌制胜的战略。不同的棋局比银河里的原子还要多。这些仅仅是琐碎的问题,说明为下棋的计算机编制程序时面临的难题。事实上这是一个极难解决的难题,即使是最周密的程序也不能和象棋大师匹敌,这是不足为奇的。
不是哥们你这跟不上时代了呀, 看看今天的 ai 呢.
这是个我们不久就要面临的实际问题。地球与火星之间,无线电波要走4分钟左右。毫无疑问,太空人今后必须改变谈话的习惯,说起话来不能再是你一句我一句,而必须使用长长的独白,自言自语。这种通话方式与其说是对话,不如说是通信。作为另外一个例子,佩恩(RogerPayne)指出,海洋的音响效果具有某些奇特的性质,这意味着座头鲸发出的异常响亮的“歌声”在理论上可以传到世界各处,只要它们游在海水的某一特定深度上。座头鲸是否真的彼此进行远距离通话,我们不得而知,如果真有其事的话,它们所处的困境就像火星上的宇航员一样。 按照声音在水中传播的速度,座头鲸的歌声传到大西洋彼岸然后等对方的歌声再传回来,前后需要两小时左右。在我看来,座头鲸的独唱往往持续8分钟,其间并无重复之处,然后又从头唱起,这样周而复始地唱上好多遍,每一循环历时8分钟左右,其原因就在于此。
小说中的仙女座人也是这样做的。他们知道,等候对方的回音是没有实际意义的,因此他们把要讲的话集中在一起,编写成一份完整的长篇电文,然后向空间播送,每次历时数月,以后又不断重复。不过,他们发出的信息和鲸鱼的却大相径庭。仙女座人的信息是用电码写成的,它指导别人如何建造一台巨型计算机并为它编制程序。这份电文使用的当然不是人类的语言,但对熟练的密码员来说,几乎一切密码都是可以破译的,尤其是密码设计者本来的意图就是让它便于破译。这份电文首先被班克(JodrellBank)的射电望远镜截获,电文最后也被译出。按照指示,计算机终于建成,其程序亦得以付诸实施,结果却几乎为人类带来灾难,因为仙女座人并非对一切人都怀有利他主义的意图。这台计算机几乎把整个世界置于它的独裁统治之下。最后,主人公在千钧一发之际用利斧砸碎了这台计算机。
在我们看来,有趣的问题是,在什么意义上我们可以说仙女座人在操纵地球上的事务?他们对计算机的所作所为无法随时直接控制,事实上,他们甚至连计算机已经建成这个事实也无从知道,因为这些情况要经过200年才能传到他们耳中。计算机完全独立地做出决定和采取行动,它甚至不能再向它的主人请教一般的策略性问题。由于200年 的障碍难以逾越,一切指示都必须事先纳入程序。原则上,这和计算机下棋所要求的程序大致相同,但对当地情况具有更大的灵活性和适应能力。这是因为这样的程序不仅要针对地球上的情况,还要针对具有先进技术的形形色色的世界,这些世界的具体情况仙女座人是心中无数的。
正像仙女座人必须在地球上建立一台计算机来为他们逐日做出决定一样,我们的基因必须建立一个大脑。但是基因不仅是发出电码指示的仙女座人,它们也是指示本身,它们不能直接指挥我们这些木偶的理由也是一样的——时滞。基因是通过控制蛋白质的合成来发挥作用的,这本来是操纵世界的一种强有力的手段,但必须假以时日才能见到成效。培养一个胚胎需要花上几个月的时间去耐心地操纵蛋白质。另一方面,关于行为的最重要的一点是行为的快速性,用以测定行为的时间单位不是几个月而是几秒或几分之一秒。在外部世界中某种情况发生了:一只猫头鹰掠过头顶,沙沙作响的草丛暴露了猎物,接着在顷刻之间神经系统猛然行动,肌肉跃起,猎物得以死里逃生,或成为牺牲品。基因并没有这样快的反应时间。和仙女座人一样,基因只能竭尽所能事先部署一切,为它们自己建造一台快速执行的计算机,使之掌握基因能够“预料”到的尽可能多的各种情况的规律,并为此提出“忠告”。但生命和棋局一样是变幻莫测的,事先预见到一切是不现实的。像棋局的程序编制员一样,基因对生存机器的“指令”不可能是具体细微的,它只能是一般的战略以及适用于生计的各种诀窍。
有点像训练和推理.
当座头鲸感觉也不错, 脑子再发达一点就好了.
正如扬(Young)所指出的,基因必须完成类似对未来做出预测那样的任务。当胚胎生存机器处于建造阶段时,它此后一生中可能遇到的种种危险和问题都是未知数。有谁能预言有什么食肉动物会蹲伏在哪一个树丛里伺机袭击它,或者有什么快腿活物会在它面前突然出现,之字形跑过?对于这些问题人类不能预言,基因也无能为力。但某些带有普遍性的情况是可以预见的。北极熊基因可以有把握地预先知道,它们尚未出生的生存机器将会面对一个寒冷的环境。这种预测并不是基因进行思考的结果。它们从不思考:它们只不过是预先准备好一身厚厚的皮毛,因为在以前的一些躯体内,它们一直是这样做的。这也是为什么它们仍然能存在于基因库的原因。它们也预见到大地将为积雪所覆盖,而这种预见性体现在皮毛的色泽上。基因使皮毛呈白色,从而取得伪装。如果北极的气候急剧变化以致小北极熊发现它们出生在热带的沙漠里,基因的预测就错了,它们将要为此付出代价。小熊会夭折,它们体内的基因也随之死亡。
动物界里有没有下大赌注的,或者比较保守的动物呢?我们将在第9章中看到,人们通常可以把雄性动物视为下大赌注、冒大风险的赌徒,而把雌性动物视为稳扎稳打的投资者,尤其是在雄性动物为得到配偶而相互争夺的一雄多雌的物种中。阅读本书的博物学家可以想到一些能称为下大赌注、冒大风险的物种,以及其他一些比较保守的物种。这里我要言归正传,谈谈基因如何对未来做预测这个带有更大普遍意义的主题。
参数训练过程
在一些难以预见的环境中,基因如何预测未来是个难题,解决这个难题的一个办法是预先赋予生存机器以一种学习能力。为此,基因可以通过对其生存机器发出如下指示的形式来编制程序:“下面这些会带来好处:口中的甜味、情欲亢进、适中的温度、微笑的小孩等。而下面这些会带来不快:各种痛苦、恶心、空空的肚皮、哭叫的小孩等。如果你碰巧做了某件事情之后便出现了不愉快的情况,切勿再做这种事情;在另一方面,重复做为你带来好处的任何事情。”这样编制的程序有一个好处,就是可以大大削减必须纳入原来程序的那些详尽的规则,同时可以应付事先未能预见到其细节的环境变化。在另一方面,基因仍然有必要做出某些预测。在我们列举的例子中,基因估计吃糖和交配可能对基因的生存有利,在这一意义上,口中的甜味以及情欲亢进是“有益的”。但根据这个例子,它们不能预见到糖精和自慰也可能为它们带来满足。它们也不能预见到,在我们这个糖多得有点反常的环境里,糖吃得过多的危险性。
模拟
如果模拟是这样一个好办法,我们可以设想生存机器本该是首先发现这个办法的,毕竟早在地球上出现人类以前,生存机器就已经发明了人类工程学的许多其他方面的技术:透镜和抛物面反射镜、声波的频谱分析、伺服控制系统、声呐、输入信息的缓冲存储器以及其他不胜枚举的东西。这些技术都有长长的名字,其具体细节这里不必赘述。模拟到底是怎么一回事呢?在我看来,如果你自己要做出一个困难的决定,而这个决定牵涉到一些将来的未知量,你也会进行某种形式的模拟。你设想在你采取各种可供选择的步骤之后将会出现的情况。你在大脑里建立一个模型,这个模型并不是世上万物的缩影,它仅仅反映出依你看来是有关的范围内有限的一组实体。你可以在心目中看到这些事物的生动形象,或者看到并操纵它们已经概念化了的形象。无论怎样,你的大脑里不会出现一个实际上占据空间的、反映你设想的事物的模型。但和计算机一样,你的大脑怎样表现这个模型的细节并不太重要,重要的是你的大脑可以利用这个模型来预测可能发生的事。那些能够模拟未来事物的生存机器,比只会在实际的试验和误差的基础上积累经验的生存机器要棋高一筹。问题是实际的试验既费时又费精力,明显的误差常常带来致命的后果,模拟则既安全又迅速。
第5章 进犯行为:稳定性和自私的机器
属于同一物种的生存机器往往更加直接地相互影响对方的生活。发生这种情况有许多原因。原因之一是,自己物种的一半成员可能是潜在的配偶,而且对其子女来讲,它们有可能是勤奋和可以利用的双亲;另一个原因是,同一物种的成员非常相似,它们都是在同一类地方保存基因的机器,生活方式又相同,因此它们是一切生活必需资源的更直接的竞争者。对乌鸫来说,鼹鼠可能是它的竞争对手,但其重要性却远不及另一只乌鸫。鼹鼠同乌鸫可能为蚯蚓而进行竞争,但乌鸫同乌鸫不仅为蚯蚓,而且还为其他一切东西而相互争夺。如果它们属于同一性别,还可能争夺配偶。通常是雄性动物为争夺雌性配偶而相互竞争,其中道理我们在后文将会看到。这种情况说明,如果雄性动物对与之竞争的另一只雄性动物造成损害的话,也许会给它自己的基因带来好处。
因此,对于生存机器来说,合乎逻辑的策略似乎是将其竞争对手杀死,然后最好把它们吃掉。尽管自然界会发生屠杀和同类相食的现象,但认为这种现象普遍存在却是对自私基因理论的一种幼稚的理解。事实上,洛伦茨在《论进犯行为》一书中就强调过,动物间的搏斗具有克制和绅士风度的性质。他认为,动物间的搏斗有一点值得注意:它们的搏斗是一种正常的竞赛活动,像拳击或击剑一样,是按规则进行的。动物间的搏斗是一种手持钝剑或戴着手套进行的搏斗,威胁和虚张声势代替了真刀真枪,胜利者尊重降服的示意,它不会像我们幼稚的理论所能断言的那样,会给投降者以致命的打击或撕咬。
无底线的残杀是不利于本物种基因延续的.
博弈论的互相制衡
上面这段自我独白完全是为了说明:在决定要不要进行搏斗之前,最好是对“得—失”进行一番可能是无意识的,但却是复杂的权衡。尽管进行搏斗无疑会得到某些好处,但并非百利而无一弊。同样,在一场搏斗的过程中,牵涉让搏斗升级还是缓和下来的每一个策略上的决定都各有其利弊,而且这些利弊在原则上都可以进行分析。个体生态学家对这种情况早已有所了解,尽管这种了解还不太清晰明确,但只有史密斯才能有力和明确地表述这种观点,而人们通常并不认为他是一位生态学家。他同普赖斯(G.R.Price)、帕克(G.A.Parker)合作运用数学分支中被称为博弈论(Game Theory)的工具进行研究。他们独到的见解能够用语言而非数学符号表达出来,尽管其精确程度因此而有些损失。
进化稳定策略(evolutionarily stable strategy,以下简称ESS)是史密斯提出的基本概念。他追根溯源,发现最早有这种想法的是汉密尔顿和麦克阿瑟(R.H.MacArthur)。“策略”是一种程序预先编制好的行为方式。例如,“向对手进攻,如果它逃你就追,如果它还击你就逃”就是一种策略。我们所说的策略并不是个体有意识地制订出来的,弄清这一点十分重要。不要忘记,我们把动物描绘成机器人一样的生存机器,它的肌肉由一架程序预先编制好的计算机控制。用文字把策略写成一组简单的指令只是为了便于我们思考。由某种难以具体讲清楚的机制作用产生的动物行为,就好像是以这样的指令为根据的。
凡是种群的大部分成员采用某种策略,而这种策略的好处是其他策略所不及的,这种策略就是进化稳定策略或称ESS。这一概念既微妙又很重要。换句话讲,对于个体来说,最好的策略取决于种群的大多数成员在做什么。由于种群的其余部分也是由个体组成的,而它们都力图最大限度地扩大其各自的成就,因而能够持续存在的必将是这样一种策略:它一旦形成,任何举止异常的个体的策略都不可能与之比拟。在环境的一次大变动之后,种群内可能出现一个短暂的进化上的不稳定阶段,甚至可能出现波动。但一种ESS一旦确立,就会稳定下来:偏离ESS的行为将受到自然选择的惩罚。
为将这一观点用于解释进犯行为,我们来研究一下史密斯假设的一个最简单的例子。假定有一个特定的物种叫“鹰和鸽子”(这两个名称系人类的传统用法,但同这两种鸟的习性无关:其实鸽子是一种进攻性相当强的鸟)。在这个物种的某个种群中只存在两种搏斗策略。在我们这个假定的种群中,所有个体不是鹰就是鸽子。鹰搏斗起来总是全力以赴、孤注一掷的,除非身负重伤,否则绝不退却;而鸽子却只是以风度高雅的惯常方式进行威胁恫吓,从不伤害其他动物。如果鹰同鸽子搏斗,鸽子就迅即逃跑,因此鸽子不会受伤。如果是鹰同鹰进行搏斗,它们会一直打到其中一只受重伤或死亡才罢休。如果是鸽子同鸽子相遇,那就谁也不会受伤;它们长时间地摆开对峙的架势,直到它们中的一只感到疲劳了,或者感到厌烦而决定不再对峙下去,从而做出让步为止。我们暂且假定一个个体事先无法知道它的对手是鹰还是鸽子,只有在与之进行搏斗时才能弄清楚,而且它也记不起过去同哪些个体进行过搏斗,因此无从借鉴。
现在,作为一种纯粹是随意规定的比赛规则,我们规定竞赛者“得分”标准如下:赢一场50分,输一场0分,重伤者—100分,使竞赛拖长而浪费时间者—10分。我们可以把这些分数视为能够直接转化为基因生存的筹码。得分高而平均“盈利”也高的个体就会在基因库中遗留下许多基因。在现实中,实际的数值对分析并无多大意义,但却可以帮助我们去思考这一问题。
鹰在同鸽子搏斗时,鹰是否有击败鸽子的倾向,对此我们并不感兴趣,这一点是重要的。我们已经知道这个问题的答案了:鹰永远会取胜。我们想要知道的是:究竟鹰和鸽子谁是进化稳定策略型?如果其中一种是ESS型而另一种不是,那么我们认为属于ESS型的那种才会进化。从理论上讲,存在两种ESS型是可能的。不论种群大多数成员所采取的碰巧是什么样的策略——鹰策略也好,鸽子策略也好——对任何个体来说,如果最好的策略是随大流的话,那么,存在两种ESS型是可能的。在这种情况下,种群一般总是保持在自己的两种稳定状态中它首先达到的那一种状态。然而我们将会看到,这两种策略,不论是鹰的策略还是鸽子的策略,事实上单凭其自身不可能在进化上保持稳定性,因此我们不应该指望任何一个会得以进化。为了说明这一点,我们必须计算平均盈利。
假设有一个全部由鸽子组成的种群。不论它们在什么时候进行搏斗,谁也不会受伤。这种比赛都是一些时间拖得很长、按照仪式进行的竞赛,也许是虎视眈眈地对峙,只有当一个对手让步,这种竞赛才宣告结束。于是得胜者因获取有竞争性的资源而得50分,但因长时间的对峙而浪费时间得—10分,因此净得40分。而败方也因浪费时间得—10分。每只鸽子平均输赢各半。因此每场竞赛的平均盈利是40分和—10分的平均数,即15分。所以,鸽子种群中每只鸽子看来成绩都不错。
但是现在假设在种群中出现了一个突变型的鹰。由于它是周围唯一的一只鹰,因此它的每一次搏斗都是同鸽子进行的。鹰对鸽子总是保持不败纪录,因此它每场搏斗净得50分,而这个数字也就是它的平均盈利。由于鸽子的盈利只有15分,因此鹰享有巨大的优势。结果鹰的基因在种群内得以迅速散布。但鹰却再也不能指望它以后遇到的对手都是鸽子了。再举一极端例子,如果鹰基因的成功扩散使整个种群都变成了鹰的天下,那么所有的搏斗都变成鹰同鹰之间的搏斗,这时情况就完全不同了。当鹰与鹰相遇时,其中一个受重伤,得—100分,而得胜者得50分。鹰种群中每只鹰在搏斗中可能胜负各半,因此,它在每场搏斗中平均可能得到的盈利是50分和—100分的对半,即—25分。现在让我们设想一下一只生活在鹰种群中孑然一身的鸽子的情景吧。毫无疑问,它每次搏斗都要输掉,但它绝不会受伤。因此,它在鹰种群中的平均盈利为0分,而鹰种群中的鹰平均盈利却是—25分,鸽子的基因就有在种群中散布开来的趋势。
按照我的这种叙述方式,好像种群中存在一种连续不断的摇摆状态。鹰的基因扶摇直上迅速占据优势;鹰在数量上占据多数的结果是,鸽子基因必然受益,继而数量增加,直到鹰的基因再次开始繁衍,如此等等。然而情况并不一定是这样摇摆动荡。鹰同鸽子之间有一个稳定的比例。你只要按照我们使用的任意规定的评分制度计算一下的话,就能得出其结果是鸽子同鹰的稳定比例为 5:7。在达到这一稳定比例时,鹰同鸽子的平均盈利完全相等。因此,自然选择不会偏袒甲而亏待乙,而会一视同仁。如果种群中鹰的数目开始上升,不再是 5:7,鸽子就会开始获得额外的优势,比例会再回复到稳定状态。如同我们将要看到的性别的稳定比例是50∶50一样,在这一假定的例子中,鹰同鸽子的稳定比例是7∶5。在上述的两种比例中,如果发生偏离稳定点的摇摆,这种摆动的幅度也不一定很大。
更多的策略
当然,鹰同鸽子的故事简单得有点幼稚。这是一种“模式”,虽然这种情况在现实自然界中不会发生,但它可以帮助我们去理解自然界实际发生的情况。模式可以非常简单,如我们假设的模式,但对理解一种论点或得出一种概念仍旧是有助益的。简单的模式能够加以丰富扩展,使之逐渐形成更加复杂的模式。如果一切顺利的话,随着模式渐趋复杂,它们也会变得更像实际世界。要发展鹰和鸽子的模式,一个办法就是引进更多的策略。鹰和鸽子并不是唯一的可能性。史密斯和普赖斯介绍的一种更复杂的策略被称为还击策略者(Retaliator)。
还击策略者在每次搏斗开始时表现得像鸽子,就是说它不像鹰那样,开始进攻就孤注一掷,凶猛异常,而是摆开通常那种威胁恫吓的对峙姿态,但是对方一旦向它进攻,它即还击。换句话说,还击策略者当受到鹰的攻击时,它的行为像鹰;当同鸽子相遇时,它的行为像鸽子;而当它同另一个还击策略者遭遇时,它的表现却像鸽子。还击策略者是一种以条件为转移的策略者,它的行为取决于对方的行为。
另一种有条件的策略者称为恃强凌弱的策略者(Bully)。它的行为处处像鹰,但一旦受到还击,它就立刻逃之夭夭。还有一种有条件的策略者是试探性还击策略者(Prober-retaliator)。它基本上像还击策略者,但有时也会试探性地使竞赛短暂地升级。如果对方不还击,它坚持像鹰一样行动;如果对方还击,它就回复到鸽子的那种通常的威胁恫吓姿态。如果受到攻击,它就像普通的还击策略者一样进行还击。
如果将我提到的5种策略都放进一个模拟计算机中去,使之相互较量,结果其中只有一种,即还击策略,在进化上是稳定的。试探性还击策略近乎稳定。鸽子策略不稳定,因为鹰和恃强凌弱者会侵犯鸽子种群。由于鹰种群会受到鸽子和恃强凌弱者的进犯,因此鹰策略也是不稳定的。由于恃强凌弱者种群会受到鹰的侵犯,恃强凌弱者策略也是不稳定的。在由还击策略者组成的种群中,由于其他任何策略也没有还击策略本身取得的成绩好,因此它不会受其他任何策略的侵犯。然而鸽子策略在纯由还击策略者组成的种群中也能取得相等的好成绩。这就是说,如果其他条件不变,鸽子的数目会缓慢地逐渐上升。如果鸽子的数目上升到相当大的程度,试探性还击策略(而且连同鹰和恃强凌弱者)就开始获得优势,因为在同鸽子的对抗中它们要比还击策略取得更好的成绩。试探性还击策略本身不同于鹰策略和恃强凌弱策略,在试探性还击策略的种群中,只有其他一种策略,即还击策略,比它取得的成绩好些,而且也只是稍微好一些。在这一意义上讲,它几乎是一种ESS。因此我们可以设想,还击策略和试探性还击策略的混合策略可能趋向于占绝对优势,在这两种策略之间也许甚至有幅度不大的摇摆,同时占比例极小的鸽子在数量上也有所增减。我们不必再根据多态性去思考问题,因为根据多态性,每一个个体永远是不采用这种策略,就是采用另一种策略。每一个个体事实上可以采用一种还击策略、试探性还击策略以及鸽子策略三者相混合的复杂策略。
没有一个绝对的最优化的策略, 好坏都是相对的, 此消彼长, 循环往复.
只能说存在一些比较稳定的策略, 比如还击策略和试探性还击策略.
和一报还一报策略类比一下.
1. “还击策略”对应“一报还一报”吗?背景是竞争与合作的区别吗?
是的,它们在底层数学逻辑上是绝对的“异父异母的亲兄弟”。
- 逻辑同构:
- “还击策略(Retaliator)”:开局选和平(鸽子) 对方和平我也和平 对方攻击(鹰)我必反击(鹰) 对方停手我回和平。
- “一报还一报(Tit for Tat)”:开局选合作 对方合作我合作 对方背叛我必背叛 对方改过我原谅。
- 它们完美共享了四个特质:善良(不率先发难)、可激怒(遭受攻击必定向对方施加惩罚成本)、宽容(对方退让则恢复和平)、简单清晰。
- 背景区别:
- 《自私的基因》里的“鹰鸽博弈”通常描述的是单次相遇的零和/负和竞争(两只动物偶然抢一块肉)。
- 计算机锦标赛里的“囚徒困境”描述的是重复博弈的非零和合作(两个人长期做生意,可以双赢)。
2. 为什么“试探性还击策略”在这个场景下是有优势的?
这就引出了演化博弈论中一个非常深刻的现象——“和平的腐化”与“基因漂变”。
在书中,道金斯提到纯粹的“还击策略”种群有一个致命漏洞:它无法淘汰“纯鸽子”。
- 假设一个种群里100%都是“还击者”。因为大家都奉行“人不犯我,我不犯人”,所以这个社会表面上无比和平,全是用鸽子的仪式在虚张声势,永远打不起来。
- 这时候,如果基因突变,诞生了一只“纯鸽子”。这只纯鸽子在这个社会里如鱼得水,因为没有人会真正攻击它,它和“还击者”的得分一模一样。
- 在没有自然选择压力(惩罚)的情况下,由于随机的基因漂变,纯鸽子的数量会在种群中慢慢上升。 整个种群开始变得“软弱”。
- 一旦鸽子多起来,那些嗜血的“纯鹰”或者“恃强凌弱者”就会趁虚而入,疯狂收割鸽子,导致整个和平体系崩溃。
这就是“试探性还击策略(Prober-retaliator)”大显身手的地方。它的优势在于:它可以当作清理鸽子的“清道夫”或“免疫系统”。
- 它平时像个好人,但偶尔会“手贱”打别人一下(试探)。
- 如果它打到了“还击者”,对方立刻亮出獠牙,它就赶紧认怂退回和平状态(损失很小)。
- 如果它打到了“纯鸽子”,鸽子会直接逃跑!于是它兵不血刃地独占了50分的资源(收益极大)。
因此,试探性还击策略在鸽子泛滥的社会里,能获得比纯粹还击策略更高的分数。它通过偶尔的试探,把那些企图搭便车、不劳而获的“纯鸽子”全部剥削出局,从而客观上维持了整个种群“带有锋芒的武德”。
3. 为什么计算机实验中“一报还一报”独占鳌头,这里却有两个稳定策略?
这是由于**博弈规则的根本差异(重复 vs 单次)**造成的。
- 在阿克塞尔罗德的计算机实验中(重复博弈):
两个人要互动成百上千回合。“试探(主动背叛一次)”的成本极其高昂。如果你对“一报还一报”进行一次试探,对方下一轮必然报复你,然后你再报复对方……双方会陷入无休止的**“死亡螺旋(Death Spiral)”**,把双赢的红利全部砸碎。在长期合作中,“手贱”的代价太大,所以绝对不率先背叛的“一报还一报”成为了唯一王者。 - 在鹰鸽博弈中(单次随机相遇):
动物们在丛林中随机相遇,打完这一架,这辈子可能都不会再见(没有记忆,无法建立长期信任)。在没有长远未来的情况下,“试探一下,发现对方是硬茬就跑,发现是软柿子就吃掉”,是一种收益极高、风险可控的策略。
宏观的哲学结论:没有绝对的乌托邦
道金斯这段话不仅是数学推演,更揭示了生态学和人类社会运转的冷酷铁律:
- 没有绝对完美、静态的单一策略。
正如你总结的:“没有一个绝对的最优化的策略,好坏都是相对的,此消彼长,循环往复。” 如果人人都当不惹事的好人(还击者),必然会滋生出懦弱的羊(鸽子),羊多了必然引来狼(鹰或试探者)。 - 系统的稳定性建立在“动态混合”之上。
道金斯最后指出,真正的进化稳定策略(ESS)往往不是全体成员死守一种教条,而是一种混合策略的动态平衡(比如种群中保持绝大多数的还击者,少量的试探者,和极少量的鸽子)。
试探性还击者的存在,用通俗的话说,就是社会中必须存在一定比例的“刺头”或“微小的压力源”。它们的存在虽然偶尔打破和谐,但却不断地在测试系统的底线,防止整个种群退化成毫无抵抗力的羔羊。
制衡
石头剪刀布
史密斯所思考的另一类战争游戏叫作“消耗战”。我们可以认为,这种“消耗战”发生在从不参加危险战斗的物种中,也许是盔甲齐全的一个物种,它受伤的可能性很小。这类物种中的一切争端都是按传统的方式摆摆架势来求得解决的。竞赛总是以参加竞赛的一方让步而告终。你要是想赢得胜利,只要虎视眈眈地注视着对方,坚持到底毫不动摇,直到对方最终逃走。显然任何动物都不能够无限期地进行威胁恫吓,因为其他地方还有重要的事情要做。它为之竞争的资源诚可宝贵,但其价值也并非无限。它的价值只值得花这么多时间,而且正如拍卖一样,每一个人只准备出那么多钱。时间就是这种只有两个出价人参加的拍卖中使用的筹码。
我们假定所有这些个体都事先精确估计某一种具体资源(如雌性动物)值得花多长时间,那么一个打算为此稍微多花一点时间的突变性个体就永远是胜利者。因此,出价极限固定不变的策略是不稳定的。即使资源的价值能够被非常精确地估计出来,而且所有个体的出价也都恰如其分,这种策略也是不稳定的。任何两个个体按照极限策略出价,它们会在同一瞬间停止喊价,结果谁也没有得到这一资源!在这种情况下,与其在竞赛中浪费时间,倒不如干脆一开始就弃权来得划算。消耗战同实际拍卖之间的重要区别在于,在消耗战中参加竞赛的双方毕竟都要付出代价,但只有一方得到这项资源。所以,在极限出价者的种群中,竞赛一开始就弃权的策略会获得成功,从而也就在种群中扩散开来。其结果必然是,对于那些没有立刻弃权而是在弃权之前稍等那么几秒钟的个体来说,它们可能得到的某些好处开始增长起来。这是一种用以对付已经在种群中占绝对优势的那些不战而退的个体的有利策略。这样,自然选择促进个体在弃权之前坚持一段时间,使这段时间逐渐延长,直至再次延长到有争议的资源的实际经济价值所容许的极限。
谈论之际,我们不知不觉又对种群中的摇摆现象进行了描述。然而数学上的分析再次表明,这种摇摆现象并非不可避免。进化稳定策略是存在的,它不仅能够以数学公式表达出来,而且能用语言这样来说明:每一个个体在一段不能预先估计的时间内进行对峙,就是说,在任何具体场合难以预先估计,但按照资源的实际价值可以得出一个平均数。举例说,假如该资源的实际价值是5分钟的对峙,在进化稳定策略中,任何个体都可能持续5分钟以上,或者少于5分钟,或者恰好5分钟。重要的是,对方无法知道在这一具体场合中它到底准备坚持多长时间。
石头: 极限出价策略, 肯投入的成本极高, 但遇到同类时损失也极大.
剪刀: 演戏策略, 弃权前等几秒种, 装模做样一下.
布: 弃权策略, 遇到竞争者直接放弃.
愣的怕横的, 横的怕不要命的.
美妙的互相制衡.
有些人也许不理解为什么布克制石头, 虽然二者相遇时一定是石头取得资源, 但是在一个全是石头的种群里, 石头所要承担的损失风险是远大于布的, 这时候布的生存优势反而会比石头高.
这叫什么, 天道轮回, 以柔克刚.
三竦
用 “凶恶蠢” 这三个字概括三种策略.
凶克恶, 恶克蠢, 蠢克凶.
凶 恶 蠢 石头 剪刀 步 蛇 蛤蟆 蛞蝓 傲娇 腹黑 天然
在消耗战中,个体对于它准备坚持多久不能有任何暗示,这一点显然是极为重要的。对任何个体来说,认输的念头一旦流露,哪怕只是一根胡须抖动了一下,都会立刻使它处于不利地位。如果说胡须抖动一下就是预示在1分钟内就要退却的可靠征兆,赢得胜利的一个非常简单的策略是:“如果你的对手的胡须抖动了一下,不论你事先准备坚持多久,你都要再多等1分钟。如果你的对手是胡须尚未抖动,而这时离你准备认输的时刻已不到1分钟了,那你就立刻弃权,不要再浪费任何时间。绝不要抖动你自己的胡须。”因此,抖动胡须或预示未来行为的任何类似暴露形式都会很快受到自然选择的惩罚。不动声色的面部表情会得到发展。
为什么要面部表情不动声色,而不是公开说谎呢?其理由还是因为说谎行为是不稳定的。假定情况是这样的:在消耗战中,大部分个体只有在确实想长时期战斗下去时才把颈背毛竖起来,那么,能够发展的将是明显的相反策略:在对手竖起颈背毛时立刻认输。但这时说谎者的队伍有可能开始逐渐形成。那些确实无意长时间战斗下去的个体在每次对峙中都将其颈背毛竖起,于是胜利的果实唾手可得。说谎者基因因此扩散开来。在说谎者成为多数时,自然选择就又会有利于那些能够迫使说谎者摊牌的个体,因而说谎者的数目会再次减少。在消耗战中,说谎和说实话同样都不是进化稳定策略,不动声色的面部表情方是进化稳定策略,即使最终认输,也是突如其来和难以预料的。
胸有惊雷而面如平湖.
泰山崩于前而面不改色.
说谎要能成功, 前提是别人必须相信你的谎言, 一旦说谎者增多, 谎言就会被识破.
自然选择就会奖励那些无视谎言直接逼迫摊牌的个体, 在摊牌者的逼迫下, 说谎者就会吃大亏, 从而被淘汰. 说谎者自己促成了消灭自己的力量, 所以是不稳定的.
在这个假设下, 竖起颈背毛其实是发出了一种信号, 起到什么作用还要看对方怎么解读这个信号.
| 策略 | 是否发出信号 | 如何解读对方发出的信号 |
|---|---|---|
| 诚实者 | / | 对方准备死磕到底 |
| 骗子 | 是 | / |
| 摊牌者 | / | 对方是在装腔作势 |
| 扑克脸 | 否 | 不解读 |
骗子克制诚实者
摊牌者克制骗子
诚实者克制摊牌者
扑克脸不搞这一套, 所以无法选中.
这启示我们不要搞太多虚的东西, 抓住真正重要的 , 少想多做.
大音希声,大象无形;胜者无迹,故无可乘。
第6章 基因种族
我在第3章中曾强调过,基因确实能产生多种影响,这是事实。从纯理论的角度上说,出现这样的基因是可能的,它能赋予个体以一种明显可见的外部“标志”,如苍白的皮肤、绿色的胡须,或其他引人注目的东西,以及对其他带有这些标志的个体特别友好的倾向。这样的情况可能发生,尽管可能性不大。绿胡须同样可能与趾甲往肉里长或其他特征的倾向有关,而对绿胡须的偏好同样可能与嗅不出小苍兰的生理缺陷同时存在。同一基因既产生正确的标志又产生正确的利他行为,这种可能性不大。可是,这种我们可以称之为绿胡须利他行为效果的现象在理论上是可能的。
像绿胡须这种任意选择的标志不过是基因借以在其他个体中“识别”其自身拷贝的一个方法而已。还有没有其他方法呢?下面可能是一个非常直接的方法。单凭个体的利他行为就可以识别出拥有利他基因的个体。如果一个基因能“说”类似“喂!如果A试图援救溺水者而自己快要没顶,就跳下去把A救起来”这样的话,这个基因在基因库中就会兴旺起来,因为A体内多半含有同样的救死扶伤的利他基因。A试图援救其他个体的事实本身就是一个相当于绿胡须的标志。尽管这个标志不像绿胡须那样荒诞不经,但它仍然有点令人难以置信。基因有没有一些比较合乎情理的办法“识别”存在于其他个体中的拷贝呢?
回答是肯定的。我们很容易证明,近亲多半共有同样的基因。人们一直认为,这显然是亲代对子代的利他行为如此普遍存在的理由,费希尔、霍尔丹[插图],尤其是汉密尔顿认为,这种情况同样也适用于其他近亲——兄弟、姐妹、侄子侄女和血缘近的堂(表)兄弟或姐妹。如果1个个体为了拯救10个近亲而牺牲,操纵个体对亲属表现利他行为的基因可能因此失去一个拷贝,但同一基因的大量拷贝却得以保存。
血缘关系是最简便用于基因识别的方式.
一般的亲缘关系计算方法
这里有一个简便的方法供你计算任何两个个体A和B的亲缘关系。如果你要立遗嘱或需要解释家族中某些成员之间为何如此相像,你就可能发觉这个方法很有用。在一般情况下,这个方法是行之有效的,但在发生近亲相互交配的情况下就不适用了。某些种类的昆虫也不适用于这个方法,我们在下面会谈到这个问题。
首先,查明A和B所拥有的共同祖先是谁。譬如说,一对第一代堂兄弟的共同祖先是他们的祖父和祖母。找到一个共同祖先以后,他的所有祖先当然也就是A和B的共同祖先,这当然是合乎逻辑的。不过,对于我们来说,查明最近一代的共同祖先就足够了。从这个意义上说,第一代堂兄弟只有两个共同的祖先。如果B是A的直系亲属,譬如说是A的曾孙,那么我们要找的“共同祖先”就是A本人。
找到A和B的共同祖先之后,再按下列方法计算代距(generation distance)。从A开始,沿其家谱上溯其历代祖先,直到你找到他和B所共有的那一个祖先为止,然后再从这个共同祖先往下一代一代数到B。这样,在家谱上从A到B的世代总数就是代距。譬如说,A是B的叔叔,那么代距是3,共同的祖先是A的父亲,亦即B的祖父。从A开始,你只要往上追溯一代就能找到共同的祖先,然后从这个共同的祖先往下数两代便是B。因此,代距是1+2=3。

出五服
五等
1. 第一等/第二等:斩衰、齐衰
- 关系: 父母与子女(),同胞兄弟姐妹(),祖父母与孙子女()。
- 代距: 或 (通过共同祖先)。这是关系最紧密的直系与旁系血亲。
2. 第三等:大功
- 关系: 第一代堂兄弟姐妹(共同祖先是祖父母,共2人)。
- 代距计算:
- 亲缘指数:
3. 第四等:小功
- 关系: 第二代堂兄弟姐妹(从堂兄弟,共同祖先是曾祖父母,共2人)。
- 代距计算:
- 亲缘指数:
4. 第五等:缌麻(五服的极限边缘)
- 关系: 第三代堂兄弟姐妹(族兄弟,共同祖先是高祖父母——即爷爷的爷爷,共2人)。
- 代距计算:
- 亲缘指数:
- 这是有服丧义务的最远边界。
什么是“出五服”?
“出五服”指的是第四代堂兄弟姐妹(四从兄弟)及更远的关系。
- 血缘关系: 他们的共同祖先需要再往上数一代,到了烈祖(高祖的父亲)。
- 代距计算: 从A上溯5代到烈祖,再下推5代到B,代距 。
- 亲缘指数:
在中国传统宗族社会中,一旦出了五服(第四代堂亲),“亲已尽,行同路人” —— 彼此之间在法律和礼制上已经没有了服丧的义务,宗族谱系通常也不再强求将两支系合起来祭祀,在旧时代甚至被允许通婚(即便同姓,出五服后的遗传风险也已降至极低)。
东方传统与西方演化论的奇妙交汇
正如道金斯在书中所写:
“至于远如第三代堂兄弟或姐妹的亲缘关系[]……就一个利他基因而言,一个第三代的堂兄弟姐妹的亲缘关系和一个素昧平生的人差不多。”
- 道金斯的科学结论: 当亲缘指数衰减到 (第三代堂亲)甚至更低时,利他基因在他们身上复制存活的概率,已经和种群中的任意一个陌生人几乎没有区别。在演化选择上,个体没有动力再去为他们进行自我牺牲。
- 中国古人的社会直觉: 到了第三代堂亲(缌麻,),宗族温情和凝聚力达到了物理极限。一旦到了第四代堂亲(出五服,),血缘关系彻底淡化,彼此不再被视作一家人。
Note
- 一:自己(己身)
- 关系指数:
- 二:同胞兄弟姐妹(共同祖先:父母,向上数2代)
- 关系指数:
- 丧服级别:一服(斩衰)/ 二服(齐衰)
- 三:第一代堂/表兄弟姐妹(共同祖先:祖父母,向上数3代)
- 关系指数:
- 丧服级别:三服(大功)
- 四:第二代堂/表兄弟姐妹(从堂/再从兄弟,共同祖先:曾祖父母,向上数4代)
- 关系指数:
- 丧服级别:四服(小功)
- 五:第三代堂/表兄弟姐妹(三从/族兄弟,共同祖先:高祖父母,向上数5代)
- 关系指数:
- 丧服级别:五服(缌麻) —— 到此为止是五服的边界。
- 六:第四代堂/表兄弟姐妹
- 关系指数:
- 丧服级别:无需丧服 —— 出五服。
中国现行法律允许通婚的最近亲缘是从第二代堂/表兄弟姐妹开始.
.
美味骨科的甜蜜点, 平时能串门走亲戚, 还可以给对方家里人服丧的.
我们因此可以得出这样的结论:就利他行为的演化而言,“真正的”亲缘关系的重要性可能还不如动物对亲缘关系做出的力所能及的估计。懂得这个事实就懂得在自然界中,父母之爱为什么比兄弟/姐妹之间的利他行为普遍得多而且真诚得多,也就懂得为什么对动物而言其自身利益甚至比几个兄弟更为重要。简单地说,我的意思是,除了亲缘关系指数以外,我们还要考虑“肯定性”的指数。尽管父母/子女的关系从遗传学的意义上说,并不比兄弟/姐妹的关系来得密切,它的肯定性却大得多。在一般情况下,要肯定谁是你的兄弟就不如肯定谁是你的子女那么容易。至于你自己是谁,那就更容易肯定了。
我们已经谈论过海鸠之中的骗子,在以后的几章里,我们将要谈到说谎者、骗子和剥削者。在这个世界上,许多个体为了自身的利益总是伺机利用其他个体的亲属选择利他行为,因此,一个生存机器必须考虑谁可以信赖,谁确实是可靠的。如果B确实是我的弟弟,我照顾他时付出的代价就该相当于我照顾自己时付出的代价的一半,或者相当于我照顾我自己的孩子时付出的代价。但我能够像我肯定我的儿子是谁那样去肯定他是我的弟弟吗?我如何知道他是我的弟弟呢?
如果C是我的同卵孪生兄弟,那我照顾他时付出的代价就该相当于我照顾自己的任何一个儿女的两倍,事实上,我该把他的生命看作和我自己的生命一样重要。但我能肯定他是我的同卵孪生兄弟吗?当然他有点像我,但很可能我们碰巧有同样的容貌基因。不,我可不愿为他牺牲,因为他的基因有可能全部和我的相同,但我肯定知道我体内的基因全部是我的。因此,对我来说,我比他重要。我是我体内任何一个基因所能肯定的唯一的一个个体。再说,在理论上,一个操纵个体自私行为的基因可以由一个操纵个体利他行为,援救至少一个同卵孪生兄弟或两个儿女、兄弟,或至少4个孙子孙女等的等位基因代替,但操纵个体自私行为的基因具有一个巨大的优越条件,那就是识别个体的肯定性。与之匹敌的以亲属为对象的利他基因可能会搞错对象,这种错误可能纯粹是偶然的,也可能是由骗子或寄生者蓄意制造的。因此,我们必须把自然界中的个体自私行为视为是不足为奇的,这些自私行为不能单纯用遗传学上的亲缘关系来解释。
在许多物种中,做母亲的比做父亲的更能识别谁是它们的后代。母亲生下有形的蛋或孩子,它有很好的机会去辨识它自己的基因传给了谁。而可怜的爸爸受骗上当的机会就大得多。因此,父亲不像母亲那样乐于为抚养下一代而操劳,那是很自然的。在第9章《两性战争》里,我们将看到造成这种情况还有其他的原因。同样,外祖母比祖母更能识别谁是它的外孙或外孙女,因此,外祖母比祖母表现出更多的利他行为是合乎情理的。这是因为她能识别她的女儿的儿女。外祖父识别其外孙或外孙女的能力相当于祖母,因为两者都是对其中一代有把握而对另一代没有把握。同样舅舅对外甥或外甥女的利益应比叔叔或伯伯更感关切。在一般情况下,舅舅应该和舅母一样表现出同样程度的利他行为。确实,在不贞行为司空见惯的社会里,舅舅应该比“父亲”表现出更多的利他行为,因为它有更大的理由信赖同这个孩子的亲缘关系。它知道孩子的母亲至少是它的异父或异母姐妹,“合法的”父亲却不明真相。我不知道是否存在任何证据,足以证明我提出的种种臆测。但我希望,这些臆测可以起到抛砖引玉的作用,其他的人可以提供或致力于搜集这方面的证据,特别是社会人类学家或许能够发表一些有趣的议论吧。
第7章 计划生育
生育与抚养是两个事情
有人主张把父母的关怀同其他类型的亲属选择利他行为区别开来,这种主张的道理是不难理解的。父母的关怀看起来好像是繁殖的组成部分,而诸如对待侄子的利他行为却并非如此。我认为这里确实隐藏着一种重要的区别,不过人们把这种区别弄错了。他们将繁殖和父母的关怀归在一起,而把其他种类的利他行为另外归在一起。但我却希望这样区分:一类为生育新的个体,另一类为抚养现存的个体。我把这两种活动分别称为生育幼儿和照料幼儿。个体生存机器必须做两类完全不同的决定,即抚养的决定和生育的决定。“决定”这个词用在这里是指无意识的策略上的行动。思考是否做抚养的决定的形式是:“有一个幼儿,它同我在亲缘关系上的接近程度如此这般,如果我不喂养它,它死亡的机会如何如何,那么我要不要喂养它?”另一方面,是否做生育的决定的思考形式是这样的:“我要不要采取一切必要的步骤以便生育一个新的个体?我要不要繁殖?”在一定程度上,抚养和生育必然为占用某个个体的时间和其他资源而相互竞争,这个个体可能不得不做出选择:“我抚养这个幼儿好呢,还是再生一个好?”
抚养和生育的各种混合策略,如能适应物种生态上的具体情况,在进化上是能够稳定的。单纯的抚养策略在进化上不可能稳定。如果所有个体都付出全部精力去抚养现有的幼儿,以至于连一个新的个体也不生产,这样的种群很快就会受到精于生育的突变个体的入侵。抚养只有作为混合策略的一部分,才能取得进化上的稳定——至少需要进行某种数量的生育活动。
我们非常熟悉的物种——哺乳动物和鸟类——往往都是抚养的能手。伴随着生育幼儿的决定的通常是抚养它的决定。正是因为生育同抚养这两种活动实际上时常相继发生,因此人们把这两件事情混为一谈。但从自私基因的观点来看,生存机器抚养的幼儿是兄弟或者是儿子,原则上是没有区别的。这一点我们在上面已提到过。两个幼儿同你的亲缘关系是相等的,如果你必须在两个要喂养的幼儿之间做出选择的话,没有任何遗传上的理由非要你选择自己的儿子不可。但另一方面,根据定义,你不可能生育自己的弟弟,你只能在其他人生出他之后抚养他。关于个体生存机器对其他已经存在的个体要不要采取利他行为,怎样才能做出理想的决定,我们在前面一章中已有论述。我们在本章要探讨一下,个体生存机器对于要不要生育新个体应如何做出决定。
gay 一般都是很好的叔叔, 对待侄子像亲孩子一样.
任何具体物种的窝卵数或胎仔数都相当固定:任何动物都不会无限制地生育后代。分歧不在于出生率是否得到调节,而在于怎么得到调节:计划生育是通过什么样的自然选择过程形成的呢?概括地说,分歧在于:动物控制生育是利他性的,为了群体的整体利益而控制生育,还是自私性的,为了进行繁殖的个体的利益而控制生育?我将对这两种理论逐一进行论述。
雄竞
许多以某种模糊的类群选择观点来看问题的人,认为这是件“好事”温-爱德华兹的解释就更加大胆:比起等级低的个体,等级高的个体有更多的机会去繁殖,这种情况不是由于它们为雌性个体所偏爱,就是因为它们以暴力阻止等级低的雄性个体接近雌性个体。温-爱德华兹认为社会地位高是表示有权繁殖的另一种票证。因此,个体为社会地位而奋斗,而不是直接去争夺雌性个体,如果最终取得的社会等级不高,它们就接受自己无权生育这个事实。凡直接涉及雌性个体时,它们总是自我克制,但这些个体能不时地试图赢得较高的社会地位,因此可以说是间接地争夺雌性个体。但和涉及领地的行为一样,“自觉接受”这条规定,即只有地位高的雄性个体才能生育,根据温-爱德华兹的观点,其带来的结果是,种群的成员数字不会增长太快。种群不会先是生育了过多的后代,然后在吃过苦头以后才发现这样做是错误的。它们鼓励正式的竞赛,让其成员去争夺地位和领地,以此作为限制种群规模的手段,以便把种群的规模保持在略低于饥饿本身实际造成死亡的水平之下。
…
表面上看,用自私基因的理论似乎很难解释这个例子。这些流浪者为什么不一而再,再而三地想方设法把领地上的占有者撵走,直到它们筋疲力尽为止呢?毕竟它们这样做不会有任何损失。但且慢,也许它们的确会有所失。我们已经看到,领地的占有者一旦死亡,流浪者就有取而代之的机会,从而也就有了繁殖的机会。如果流浪者用这样的方式继承一块领地,比用搏斗的方式取得这块领地的可能性还要大,那么,作为自私的个体,它宁愿等待,以期某一个个体死亡,而不愿在无益的搏斗中浪费哪怕是一点点精力。以温-爱德华兹的观点来说,为了群体的福利,流浪者的任务就是充当替补,在舞台两侧等待,随时准备接替在群体繁殖舞台上死亡的领地占有者的位置。现在我们可以看到,对纯粹的自私个体来说,这种办法也许是它们的最佳策略。就像我们在第4章中所说的那样,我们可以把动物看作赌徒。对一个赌徒来说,有时最好的策略不是穷凶极恶地主动出击,而是坐等良机。
自私基因的理论甚至也能够解释清楚“炫耀性展示”。你应该还记得温-爱德华兹曾做这样的假设,一些动物故意成群地聚集在一起,以便为对所有的个体进行“人口普查”提供方便,并相应地调节其出生率。没有任何证据证明任何这样的聚集事实上是炫耀性的,但我们可以假定找到了这类证据。这会不会使自私基因的理论处于窘境?丝毫不会。
欧椋鸟大批群栖在一起。不妨这样假定,它们在冬季数量过剩,来年春季繁殖能力就会降低;而且,欧椋鸟倾听相互的鸣叫声也是导致其降低生殖能力的直接原因。这种情况可以用这样的实验加以证明。给一些欧椋鸟个体分别放送两种录音,一种再现了欧椋鸟稠密聚集的栖息地且鸣叫声非常洪亮,另一种再现了欧椋鸟不太稠密的栖息地且鸣叫声比较小。两相比较,前面一种欧椋鸟的产蛋量要少些。这说明,欧椋鸟的鸣叫声构成一种炫耀性展示。自私基因的理论对这种现象的解释,同它对于老鼠的例子的解释几无差别。
而且,我们是以这样的假定作为出发点的,即如果有些基因促使你生育你无法抚养的子女,那么这样的基因会自动受到惩罚,在基因库中的数量会越来越少。一个效率高的卵生动物作为自私的个体,它的任务是预见在即将来临的繁殖季节里每窝的最适量是多少。你可能还记得我们在第4章中使用的“预见”这个词所具有的特殊含义。那么雌鸟又是如何预见它每窝的最适量的呢?哪些变量会影响它的预见?许多物种做出的预见也可能是固定的,年复一年地从不变化。因此塘鹅平均每窝的最适量是1只蛋,但在鱼儿特别多的年月,一个个体的真正最适量也许会暂时提高到两只蛋,这种可能性是存在的,如果塘鹅无法事先知道某一年是否将是一个丰收年的话,我们就不能指望雌塘鹅甘冒风险,生两只蛋而浪费它们的资源,因为这有可能损害到它们在一般年景中正常的繁殖成果。
一般来说,可能还有其他物种——欧椋鸟或许就是其中之一——能在冬季预言某种具体食物资源在来年春天是否会获得丰收。农村的庄稼人有许多古老的谚语,例如说冬青果的丰产可能就是来年春季气候好的吉兆。不管这些说法有没有正确的地方,从逻辑上说预兆是可能存在的,一个好的预言者从理论上讲可以据此年复一年地按照其自身的利益调节其每窝的产蛋量。冬青果可能是可靠的预兆,也可能不是,但像在老鼠例子中的情况一样,动物个体的密度看来很可能是一个正确的预报信号。一般来说,雌欧椋鸟知道它在来年春季终于要喂养自己的雏鸟时,将要和同一物种的对手竞争食物。如果它能够在冬季以某种方式估计出自己物种在当地的密度的话,它就具备了有力的手段,能够预计明年春天为雏鸟搜集食物的困难程度。假如它发现冬天的个体密度特别高的话,出于自私的观点,它很可能采取审慎的策略,生的蛋会相对减少:它对自己的每窝最适量的估计值会随之降低。
如果动物个体真的会根据对个体密度的估计而降低其窝卵数,那么,每一个自私个体都会立即向对手装出个体密度很高的样子,不管事实是不是这样,这样做对每一个自私的个体都是有好处的。如果欧椋鸟是根据冬天鸟群栖息地声音的大小来判断个体密度的话,每只鸟会尽可能地大声鸣叫,以便听起来像是两只鸟而不是一只鸟在鸣叫,这样做对它们是有利的。一只动物同时装扮成几只动物的做法,克雷布斯在另一个场合提到过,并把这种现象称作“好动作效果”(Beau Geste Effect),这是一本小说的书名,书中讲到法国外籍军团的一支部队曾采用过类似的战术。在我们所举的例子中,这种方法用来诱使周围的欧椋鸟降低它们的窝卵数,降低到比实际的最适量还要少。如果你是一只欧椋鸟而且成功地做到这一点,那是符合你自私的利益的,因为你使不含有你的基因的个体减少了。因此,我的结论是,温-爱德华兹有关炫耀性行为的看法实际上也许是一个很正确的看法:除了理由不对之外,他所讲的始终是正确的。从更广泛的意义上来说,拉克所做的那种类型的假设能够以自私基因的语言,对看上去似乎是支持类群选择理论的任何现象都做出充分有力的解释(如果此类现象出现的话)。
- 估计个体密度, 密度高少生, 密度低多生.
- 估计密度需要一些 “征兆”, “征兆” 可能是可靠的, 也可能被伪造.
- 自私的个体会倾向于向其它同类伪造出种群密度高的 “征兆”.
这个过程被温-爱德华兹称为 “炫耀性展示”.
对“炫耀性展示(Epideictic Display)”这一现象,温-爱德华兹和理查德·道金斯给出了截然相反的科学假说。这不仅是对一个具体行为的争论,更是进化生物学史上**“群体选择”与“基因/个体选择”**两大思想范式的终极对决。
一、 两人是如何解释的?从什么角度出发?
1. 温-爱德华兹(Wynne-Edwards)
- 解释: 动物举行大规模的集体展示(如欧椋鸟黄昏大聚噪),是为了进行**“集体人口普查”**。个体通过鸣叫声和聚集密度评估环境压力。如果发现太拥挤,它们就会主动、自愿地降低自己的产卵量,实行计划生育。
- 出发角度:群体选择论(Group Selection)
- 他认为自然选择作用于**“群体”或“物种”**这一层级。
- 核心逻辑: 那些由“懂得自我克制、不自私榨干资源”的个体组成的群体,能够在历史中存活下来;而那些由“极度自私、疯狂繁殖”的个体组成的群体,会因为耗尽食物而集体灭绝。因此,自然选择筛选出了“为了物种利益”而克制生育的利他特征。
2. 理查德·道金斯(Richard Dawkins)
- 解释: 这种集体鸣叫根本不是温和的人口普查,而是一场**“高分贝谎言大赛(好动作效果/Beau Geste Effect)”。每只自私的鸟都试图发出两三只鸟的叫声,伪造“这里已经挤爆了”的假象,诱骗竞争对手**去实行计划生育,从而为自己的后代争取更多的生存空间。
- 出发角度:基因/个体选择论(Gene/Individual Selection)
- 他认为自然选择的终极作用对象是最小的复制因子——“自私的基因”。
- 核心逻辑: 生物的行为只是基因最大化复制自身的工具。动物降低产蛋量,不是为了群体不挨饿,而是因为“生了抚养不起的孩子,会导致所有孩子夭折”,这是个体最大化自身利益的自私计算。同时,通过欺诈手段让对手少生,更是自私基因消灭潜在竞争对手的精妙策略。
二、 这两种解释理论有绝对的优劣之分吗?
在现代主流演化生物学中,两者的地位有极其明确的优劣之分:
- 温-爱德华兹的“初级群体选择论”(Naive Group Selection)已经被现代科学彻底否定和抛弃。
- 致命漏洞(“内部篡夺”): 假设一个群体里100%都是高尚自律、为了物种不灭绝而主动限制生育的个体。此时,哪怕只出现一个因为基因突变而极度自私、拼命超生的个体,这个自私者的基因就会在这个“自我克制”的温床里疯狂扩散,只需几代就能将高尚者彻底淘汰。群体选择在数学模型上是极度不稳定的,无法抵御“搭便车者(Free-riders)”的内部颠覆。
- 道金斯的“基因/个体选择论”是现代进化生物学的绝对基石。
- 它在数学上极其稳固(符合ESS进化稳定策略),能完美解释自然界99%以上的个体冲突、性选择、亲子博弈和利己行为。
现代科学的微调:多层选择理论(Multilevel Selection, MLS)
虽然初级的“为了物种好”被证实是错的,但现代生物学(如E.O.威尔逊和D.S.威尔逊)将群体选择修正为了更严密的**“多层选择理论”**:
“在个体内卷中,自私者胜过利他者;但在群体竞争中,利他群体胜过自私群体。”
如果群体之间的竞争极度惨烈,且群体内部有极强的惩罚/抑制自私者的机制,那么“群体层面的选择”确实会在某些特定领域发挥作用。
三、 适用范围与具体实例
在面对不同的生物和现象时,我们需要切换不同的解释工具:
1. 必须用“基因/个体选择论”解释的现象
这类现象的特点是:群体内部竞争极度激烈,没有阻碍自私者的物理或制度边界,个体行为甚至直接损害群体利益。
- 典型例子 A:雄狮弑仔行为(Infanticide)
- 现象: 当新雄狮击败旧领主夺取狮群后,会立刻咬死所有尚在哺乳期的幼狮。
- 群体选择论的尴尬: 无法解释。杀死同类幼崽极大地损害了狮群和物种的延续,降低了种群规模。
- 基因选择论的完美解释: 极其合理。杀死非亲生幼崽可以让母狮迅速停止哺乳、重新进入发情期。新雄狮可以立刻繁衍属于自己的基因。在这里,自私的基因无情地蹂躏了“群体利益”。
- 典型例子 B:戴维·拉克(David Lack)的鸟类产卵量模型
- 现象: 很多鸟类年复一年只生固定数量的蛋,哪怕给巢里多放几个蛋它们也会排斥。
- 群体选择论: 它们为了控制物种数量,主动节制。
- 个体选择论(正确): 经过精确计算,这个产卵量是它们能喂活的上限。生5只,5只都能活;生8只,因为食物不够,最后全饿死或只活1只。鸟类是为了自身基因的最大存活率而控制产卵量,并非为了物种。
2. 适合用“(现代)群体/多层选择论”解释的现象
这类现象的特点是:群体拥有极强的物理边界,或者拥有高效惩罚自私者的“免疫系统”,导致群体间的竞争远远大于群体内部的消耗。
- 典型例子 A:微生物生物膜(Biofilms)与公共副产品
- 现象: 某些细菌(如铜绿假单胞菌)在感染宿主时,会共同向体外分泌“载铁蛋白”来抢夺宿主的铁元素。
- 解释: 载铁蛋白是公共资源(利他行为)。在试管里,不劳而获的自私细菌(只消耗、不制造)会迅速干掉老实菌,导致种群崩溃。但在现实的宿主组织(如肺部)中,细菌是呈孤立的群落(Group)分布的。那些100%由老实菌组成的群落,由于铁元素充足,会迅速干掉那些全是骗子菌的群落。 在这种空间结构明确、群体竞争极强的微生物微生态中,群体选择是维持“利他合作”的决定性力量。
- 典型例子 B:人类的文化演化与社会合作(Cultural Group Selection)
- 现象: 人类会为了毫无血缘关系的“国家”、“信仰”牺牲生命,会在陌生人社会中自觉遵守道德。
- 个体/亲缘选择的局限: 很难用纯粹的基因亲缘关系(值太低)来解释如此大规模的非亲缘利他。
- 群体选择的完美解释: 人类社会演化出了强大的文化规范和惩罚机制(法律、宗教、道德舆论),极大地压制了内部的自私者。在历史上,内部高度团结、充满自我牺牲精神的利他部落/国家,在战争中会彻底消灭或同化那些自私散沙式的群体。 人类是地球上现代群体选择最典型、最成功的应用范例。
入则无法家拂士,出则无敌国外患者,国恒亡。
大的利害被消除后, 小的利害就会被放大.
对于家庭从成员数量上进行的探讨就讲这些。现在我们开始讲家庭内部的利害冲突。做母亲的对其所有的子女都一视同仁是否总是有利?还是偏爱某个子女更有利?家庭是作为一个单一的合作整体来发挥作用,还是我们不得不面对甚至在家庭内部都存在自私和欺骗这一现实?一个家庭的所有成员是否都为创造相同的最适条件而共同努力?在什么是最适条件这个问题上是否会发生分歧?这些就是我们要在下面一章试图回答的问题。关于配偶之间是否可能有利害冲突这个问题,我们放到第9章去讨论
第8章 代际之战
让我们首先解决上一章结束时提出的第一个问题。做母亲的应该不应该有宠儿?她待子女应该不应该一视同仁,不厚此薄彼?尽管说起来可能使人感到厌烦,但我还是认为有必要再唠叨一下,像往常一样做个声明,做到有言在先,免得产生误会。“宠儿”这个词并不带有主观色彩,“应该”这个词也不带有道义上的要求。我把母亲当作一台生存机器看待,其程序的编制就是为了竭尽所能繁殖存在于体内的基因的拷贝。你我之辈都是人类,知道具有自觉的目的是怎么一回事,因此,我在解释生存机器的行为时使用带有目的性质的语言,作为一种比喻,对我是有其方便之处的。
…
我们说,母亲对待子女不一视同仁,在遗传学上是毫无根据的。她同每个子女的亲缘关系指数都一样,都是½。对她而言,最理想的策略是,她能够抚养多少子女就抚养多少,但要进行平均投资,直至子女自己开始生男育女时为止。但是,正像我们在上面已看到的那样,有些个体与其他个体相比,是更理想的寿险被保险人。一窝幼畜中,个子矮小、发育不良的和同窝其他发育正常的幼畜一样,体内有同等数量的来自母体的基因,但它的预期寿命可要短些。换句话说,如果它要和它的兄弟们一样长寿,它就需要额外的亲代投资。做母亲的可以根据具体情况做出决定,它可能发现,拒绝饲养一个个子矮小、发育不良的幼畜,将其名下应得的一份亲代投资全部分给它的兄弟姐妹反而合算。事实上母亲有时干脆把它丢给其他幼畜作为食料,或自己把它吃掉作为制造奶水的原料,这样也算上策。母猪有时吞食小猪,但它是否专挑小个子的吃,我却不得而知。
这可能就是妇女停经现象形成的原因。男性生殖能力之所以不是突然消失而是逐渐衰退的,其原因大概是,父亲对每个儿女的投资额比不上母亲。甚至对一个年迈的男人来说,只要他还能使年轻妇女生育,那么,对子女而不是对孙子孙女进行投资还是合算的。
迄今为止,我们在本章和上一章里都是从亲代,主要是从母亲的立场来看待一切问题的。我们提出过这样的问题:父母是否应该有宠儿?一般说来,对父亲或母亲而言,最理想的投资策略是什么?不过,在亲代对子代进行投资时,也许每一个幼儿都能对父母施加影响,从而获得额外的照顾。即使父母不“想”在子女之间显得厚此薄彼,难道做子女的就不能先下手为强,攫取更多的东西吗?他们这样做对自己有好处吗?更严格地说,在基因库中,那些促使子女为自私目的而巧取豪夺的基因是否会越来越多,比那些仅仅使子女接受应得份额的等位基因还要多?特里弗斯在1974年一篇题为“亲代与子代间的冲突”(“Parent-Offspring Conflict”)的论文里精辟地分析了这个问题。
一个母亲同其现有的以及尚未出生的子女的亲缘关系都是一样的。我们已经懂得,从纯粹的遗传观点来看,她不应有任何宠儿。如果她事实上有所偏爱,那也是出于因年龄或其他不同条件所造成的预期寿命的差异。就亲缘关系而言,和任何个体一样,做母亲的对其自身的“亲缘指数”是她对其子女中任何一个的密切程度的两倍,在其他条件不变的情况下。这意味着她理应自私地独享其资源的大部分,但其他条件不是不变的。因此,如果她能将其资源的相当一部分花费在子女身上,那将为她的基因带来更大的好处。这是因为子女较她年轻,更需要帮助,因而她们从每个单位投资额中所能获得的好处,必然要比她自己从中获得的好处大。促使对更需要帮助的个体而不是对自身进行投资的基因,能够在基因库中取得优势,即使受益者体内只有这个个体的部分基因。动物表现出亲代利他行为和任何形式的亲属选择行为,其原因就在于此。
幼儿的角度
现在让我们以一个幼儿的观点来看一下这个问题。就亲缘关系而言,他同他的兄弟或姐妹之间任何一个的密切程度和他母亲同其子女之间的密切程度完全一样,亲缘关系指数都是½。因此,他“希望”他的母亲用其资源的一部分对他的兄弟或姐妹进行投资。从遗传学的角度上看,他和他母亲都希望为他兄弟姐妹的利益出力,而且他们持这种愿望的程度相等。但是我在上面已经讲过,他与自己的关系比与兄弟姐妹中任何一个的关系密切两倍,因此,如果其他条件不变,他会希望母亲在他身上的投资多一些。如果你和你的兄弟同年,又同样能从一品脱母乳中获得相等的好处,那你就“应该”设法夺取一份大于应得份额的母乳,而你的兄弟也应该设法夺取一份大于应得份额的母乳。母猪躺下准备喂奶时,它的一窝小猪尖声呼叫,争先恐后地赶到母猪身旁的情景你一定见过吧。一群小男孩为争夺最后一块糕饼而搏斗的场面你也见过吧。自私贪婪似乎是幼儿行为的特征。
但问题并不这样简单。如果我和我的弟弟争夺一口食物,而他又比我年轻得多,这口食物对他的好处肯定比对我大,因此把这口食物让给他吃对我的基因来说可能是合算的。哥哥和父母的利他行为可以具有完全相同的基础,前面我已经讲过,两者的亲缘关系指数都是½,而且同年长的相比,年纪较轻的个体总是能够更好地利用这种资源。如果我体内有谦让食物的基因,我的弟弟体内有这种基因的可能性是50%。尽管这种基因在我体内的机会比我弟弟大一倍—100%,因为这个基因肯定存在我体内,但我需要这份食物的迫切性可能不到他的一半。一般说来,一个幼儿“应该”攫取大于其应得份额的亲代投资,但必须适可而止。怎样才算适可而止呢?他现存的以及尚未出生的兄弟或姐妹因他攫取食物而蒙受的净损失不能大于他从中所得利益的两倍。
一个家庭内部成员的基因是有很大相似程度的, 每个个体都会计算使自己基因延续下去的加权收益并决定策略, 权重受它们之间的亲缘关系影响.
对于母亲来说每个后代都是一样的二分之一, 默认是一视同仁的, 每个后代的初始权值都是一样的.
对于幼儿来说, 自己是一, 其它兄弟姐妹是二分之一, 所以母亲与幼儿对资源分配会有不同的意见.
如果考虑其它因素 (比如个头, 年龄) 的情况下会更复杂.
我之所以在这里提出燕子杀兄弟姐妹这种罕见行为的假设,是因为我想说明一个带有普遍意义的问题。就是说,小布谷鸟的残酷行为只不过是一个极端例子,用以说明任何一个鸟巢里都会发生这种情况。同胞兄弟之间的关系比一只小布谷鸟同它同奶兄弟的关系密切得多,但这种区别仅仅是程度问题。即使我们觉得动物之间的关系竟然会发展到不惜对亲兄弟姐妹下毒手这种程度有点难以置信,但情况没有如此严重的自私行为的例子却是很多的。这些例子说明,一个幼儿从其自私行为中得到的好处可以超过它因损害到兄弟姐妹的利益而蒙受损失的两倍有余。在这种情况下,正如断乳时间的例子一样,亲代与子代之间便会发生真正的冲突。
…
因此,在世代之间的争斗中到底哪一方有更大的可能取胜是没有一个普遍答案的。最终的结局往往是子代企求的理想条件与亲代企求的理想条件之间的某种妥协。这种争斗同布谷鸟与养父母之间的争斗相似,尽管实际上的争斗不至于那么激烈可怕,因为双方都有某些共同的遗传利益——双方只是在某种程度内或在某种敏感的时节里成为敌人。无论如何,布谷鸟惯用的策略,如欺骗、利用等,有许多也可能为其同胞兄弟或姐妹所使用,不过它们不至于走得太远,做出布谷鸟那种极端自私的行为。
这一章以及下面一章(我们将讨论配偶之间的冲突)所讨论的内容似乎是有点可怕的讽刺意味的。身为人类,父母彼此真诚相待,对子女又是如此无微不至地关怀,因此这两章甚至可能为天下父母带来难言的痛苦。在这里,我必须再次声明,我所说的一切并不牵涉有意识的动机。没有人认为子女因为体内有自私的基因而故意地、有意识地欺骗父母。同时我必须重申,当我说“一个幼儿应该利用一切机会进行哄骗……说谎、欺诈、利用……”的时候,我所谓的“应该”具有特殊的含义。我并不认为这种行为是符合道德准则的,是可取的。我只是想说明,自然选择往往有利于表现这种行为的幼儿,因此,当我们观察野生种群的时候,我们不要因为看到家属之间的欺骗和自私行为而感到意外。“幼儿应该欺骗”这样的提法意味着,促使幼儿进行欺骗的基因在基因库里处于优势地位。如果其中有什么寓意深刻的地方可供人类借鉴,那就是我们必须把利他主义的美德灌输到我们子女的头脑中去,因为我们不能指望他们的本性里有利他主义的成分。
第9章 两性战争
性别的根本区分: 配子的大小
让我们再直接回到基本原理上来,深入探讨一下雄性和雌性的根本性质。我们在第3章讨论过性的特性,但没有强调其不对称现象。我们只是简单地承认,有些动物是雄性的,另有一些是雌性的,但并没有进一步追究雄和雌这两个字眼到底是什么意思。雄性的本质是什么?雌性的根本定义又是什么?我们作为哺乳动物看到大自然以各种各样的特征为性别下定义,诸如拥有阴茎、生育子女、以特殊的乳腺哺乳、某些染色体方面的特性等等。对于哺乳动物来说,这些判断个体性别的标准是无可厚非的,但对于一般的动物和植物,这样的标准并不比把穿长裤作为判断人类性别的标准更加可靠。例如青蛙,不论雄性还是雌性都没有阴茎。这样说来,雄性和雌性这两个词也许就不具有人们普遍所理解的意义了。它们毕竟不过是两个词而已。如果我们觉得它们对于说明青蛙的性别没有用处,我们完全可以不去使用它们。如果我们高兴的话,可以任意将青蛙分成性1和性2。然而,性别有一个基本特性,可以据此标明一切动物和植物的雄性和雌性。这就是雄性的性细胞或“配子”(gametes)比雌性“配子”要小得多,数量也多得多。不论我们讨论的是动物还是植物,情况都是如此。如果某个群体的个体拥有大的性细胞,为了方便起见,我们可以称之为雌性;如果另一个群体的个体拥有小的性细胞,为了方便起见,我们可以称之为雄性。这种差别在爬行动物以及鸟类中尤为显著。它们的一个卵细胞,其大小和总的营养成分,足以喂养一个正在发育成长的幼儿长达数周。即使是人类,尽管卵子小得在显微镜下才能看见,但仍比精子大许多倍。我们将会看到,根据这一基本差别,我们就能够解释两性之间的所有其他差别。
某些原始有机体,例如真菌类,并不存在雄性和雌性的问题,尽管它们也发生某种类型的有性生殖。在被称为同配生殖(isogamy)的系统中,个体并不能被区分为两种性别,任何个体都能相互交配,不存在两种不同的配子——精子和卵子,所有的性细胞都一样,都称为同形配子(isogametes)。两个同形配子融合在一起产生新的个体,而每一个同形配子是由减数分裂产生的。如果有3个同形配子A、B和C,那么A可以和B或C融合,B可以同A或C融合。正常的性系统绝不会发生这种情况。如果A是精子,它能够同B或C融合,那么B和C肯定是卵子,而B也就不能和C融合。
性别的演化学由来
帕克以及其他人都曾证明,这种不对称现象可能是由同形配子的状态进化而来的。在所有的性细胞还可以相互交换而且体积也大致相同的时候,其中很可能有一些碰巧比其他的略大一点。略大的同形配子可能在某些方面比普通的同形配子占优势,因为它一开始就能为胎儿提供大量的食物,使其有一个良好的开端。因此那时就可能出现了一个形成较大的配子的进化趋势。但道路不会是平坦的。其体积大于实际需要的同形配子,在开始进化后会为自私性的利用行为打开方便之门。那些制造小一些的配子的个体,如果它们有把握使自己的小配子同特大配子融合的话,它们就会从中获得好处。只要使小的配子更加机动灵活,能够积极主动地去寻找大的配子,就能实现这一目的。凡能制造体积小、运动速度快的配子的个体享有一个有利条件:它能够大量制造配子,因此具有繁殖更多幼儿的潜力。自然选择有利于制造小的但能主动找到大的并与之融合的性细胞。因此,我们可以想象,有两种截然相反的性“策略”正在进化中。一种是大量投资或“诚实”策略。这种策略自然而然地为小量投资、具有剥削性质的或“狡猾”的策略开辟了道路。这两种策略的相互背驰现象一旦开始,就犹如脱缰之马势必将继续下去。介乎这两种体积之间的中间体要受到惩罚,因为它们不具有这两种极端策略中任何一种的有利条件。狡猾的配子变得越来越小,越来越灵活机动。诚实的配子却进化得越来越大,以补偿狡猾的配子日趋缩小的投资额,并变得不灵活起来,反正狡猾的配子总是会积极主动去追逐它们的。每一个诚实的配子“宁愿”同另一个诚实的配子进行融合,但是,排斥狡猾配子的自然选择压力同驱使它们钻空子的压力相比,前者较弱:因为狡猾的配子在这场进化的战斗中必须取胜,否则损失很大。于是诚实的配子变成了卵子,而狡猾的配子演变成了精子。
为什么会出现两极化的性别
理查德·道金斯在这一章中介绍的是著名的 Parker-Baker-Smith 模型(1972年提出)。这一模型完美地用博弈论解释了为什么自然界中绝大多数生物都分化成了“制造大配子(卵子)的雌性”和“制造小配子(精子)的雄性”。
为了解答你的疑惑,我们可以通过数学直觉和演化博弈的逻辑,将这三个问题逐一拆解。
一、 为什么处于二者之间的“中间型”竞争力最差?
道金斯在书里说中间型“不具有两种极端策略任何一种的有利条件”,其背后的生物学机制源于**“配子数量与合子存活率”的权衡(Disruptive Selection,分裂选择)**。
假设一个个体拥有总量为
100的能量来制造配子:
- 极端大配子(卵子,诚实策略): 每个消耗
10能量,只能制造10个。优点是营养极多,能强行保证后代存活。- 极端小配子(精子,狡猾策略): 每个消耗
0.1能量,能制造1000个。优点是数量庞大、极其灵活,寻找配偶效率极高。- 中间型配子: 每个消耗
1能量,制造100个。中间型的两难困境(双重失败):
- 在“数量竞争”上: 中间型(100个)拼不过小配子(1000个)。在寻找配偶的速度和概率上,它会被铺天盖地的小配子彻底淹没。
- 在“质量生存”上:
- 在生物学中,受精卵(合子)的存活率与它的体积呈非线性的正相关。假设受精卵体积必须达到
10才能活下来。- 如果中间型配子(体积1)与小配子(体积0.1)结合,合子体积只有
1.1,由于营养严重不足,成活率几乎为 0%,这 1 能量的投资完全打了水漂。- 如果两个中间型配子自己结合(1+1=2),合子体积也只有
2,依然会饿死。- 它唯一的生路是与大配子(10)结合(1+10=11,能活)。但大配子(卵子)在数量上极其稀少(只有10个),而且不爱移动,早就被那 1000 个疯狂游动的小配子抢先占领了,中间型几乎没有任何交配机会。
结论: 中间型配子在数量上争不过精子,在营养上比不过卵子。一旦它与精子结合,后代必死无疑;它又几乎没有机会和卵子结合。这种**“高不成低不就”**的特性,导致其基因在自然选择中被迅速惩罚并淘汰。
二、 “排斥狡猾配子的选择压力”与“驱使它们钻空子的压力”相比,前者较弱,是什么意思?
这里道金斯解释的是:既然精子(小配子)是在单方面剥削卵子(大配子),为什么卵子没有演化出一种“防御机制”来拒绝精子,只和同样富含营养的大配子结合呢?
这可以用演化生物学中著名的**“生命-晚餐原理”(Life-Dinner Principle)来解释:它取决于后果的严重性(选择压力的强弱)**。
- 对于狡猾的小配子(精子)来说:这是生死存亡的问题(Life)。
- 精子如果不去钻空子(如果不去寻找并强行刺穿、融合大配子),它和另一个精子结合(0.1+0.1=0.2),或者不结合,其后代成活率是 绝对的 0%。
- 因此,精子面临的演化压力是极限级别的。任何能让精子稍微游得更快一点、穿透力更强一点、更会钻空子的突变基因,都会获得极其巨大的选择优势。
- 对于诚实的大配子(卵子)来说:这只是稍微吃亏的问题(Dinner)。
- 如果卵子和另一个卵子结合(10+10=20),成活率是 99%。
- 如果它“退而求其次”,不小心让精子钻了空子(10+0.1=10.1),成活率依然有 85%。它只是吃了一点亏,但后代还是能活下来。
- 如果卵子为了拒绝精子,演化出一套极其复杂的“防御和筛选机制”,不仅会消耗大量能量,还可能不小心把其他大配子也拒之门外。
- 由于“被剥削”的后果并不致命,大配子去演化出“拒绝机制”的动力(选择压力)就显得相对微弱。
结论: 在这场“矛与盾”的演化军备竞赛中,精子(矛)面对的是不赢就绝后的生死压力,而卵子(盾)面对的只是收益多寡的压力。因此,精子攻破卵子防御的演化速度,永远比卵子建立完美防御的速度要快。
三、 为什么促使两极分化的基因会成为 ESS(进化稳定策略)?
我们要证明两极分化是 ESS,需要证明两点:
- 原本均匀的“同形配子”状态(Isogamy)是不稳定的。
- 一旦分裂成“精子和卵子”(Anisogamy),任何中间型突变体都无法入侵。
1. 为什么“同形配子”不稳定?
假设最初大家都是老实人,都制造体积为
1的中间型配子。
此时发生了一个突变,某个个体采取了“狡猾策略”,制造10个体积为0.1的小配子。
- 这 10 个小配子在水里游动,因为数量多,很容易和原本体积为
1的配子结合(0.1+1=1.1)。- 只要
1.1体积的合子存活率,大于同形配子(1+1=2)存活率的十分之一,那么这个狡猾个体的净繁殖产出就会超过普通老实人(因为它的配子基数是人家的10倍)。- 于是,“剥削”的狡猾基因开始迅速扩散,同形配子生态瞬间瓦解。
2. 为什么两极分化(精子+卵子)是 ESS?
一旦种群彻底分化为:雌性只产大卵子(10),雄性只产小精子(0.1)。
现在,假设有一个突变体试图挑战这个秩序,它特立独行,生产了中间型配子(1)。
这只中间型配子(1)在满是精子和卵子的世界里,命运会如何?
- 如果它遇到精子(0.1): 结合成
1.1的合子,因为缺乏卵子提供的基本营养,直接饿死。- 如果它想找卵子(10): 卵子数量极少且不爱动,它必须在水里跟成千上万个极其敏捷、数量庞大的精子竞争。它的速度和数量完全被精子吊打,根本抢不到卵子。
由于这只中间型突变体在两极分化的世界里后代成活率为零,它的基因会被瞬间淘汰。
最终结论: 一旦配子分化为了两个极端(大而少,小而多),大配子和小配子就达成了完美的、互补的互利共生。在这个状态下,任何试图回到中间路线的“叛逆基因”都会遭遇毁灭性的自然选择惩罚。因此,促使两极分化的基因是不可动摇的进化稳定策略(ESS)。
宗族与冠姓
人类中以男性为大家长式的宗族观念, 以 “冠性权” 为代表, 这种行为能够产生什么生物学上的演化优势吗? 按理说 “姓氏” 并不会直接影响个体的生存吧?
从纯粹的分子生物学角度来看,“姓氏”只是一个符号(文化模因/Meme),它既不编码蛋白质,也不直接改变人的生理结构,确实不会直接影响个体的生理存活率。
然而,在人类演化史中,“文化”与“基因”是协同进化(Gene-Culture Coevolution)的。虽然姓氏是虚构的文化产物,但以“冠姓权”和“父系宗族”为代表的文化制度,在生物学上扮演了极其强悍的**“代理工具”**角色。它们极大地解决了人类在演化中所面临的几个核心生物学难题:父系确定性、雄性亲代投资、以及大规模亲属结盟。
通过演化生物学与行为生态学的视角,这种行为背后的生物学机制和演化优势可以被拆解为以下几个维度:
1. 解决“父系不确定性”(Paternity Uncertainty)与促进“雄性亲代投资”
在哺乳动物中,母子关系在生物学上是 100% 确定的(母亲绝对知道孩子是自己生的),但父子关系在技术上存在“不确定性”(在现代 DNA 技术发明前,父亲无法在生物学上 100% 确定孩子是自己的)。
- 哺乳动物的常态: 由于存在被“戴绿帽”(抚养了其他雄性的后代,导致自身基因投资失败)的风险,绝大多数哺乳动物雄性(超过 95%)交配后就会离开,几乎不参与抚育。
- 人类的特殊性: 人类婴儿是高度“早产儿”(发育极不成熟,需要多年漫长的抚育才能存活)。仅靠母亲一人很难抚活孩子,人类演化出了极罕见的**“高水平雄性亲代投资”(Male Parental Investment, MPI)**。
- “冠姓权”的生物学功能:
雄性要付出自己一生的资源(食物、庇护所、领地安全)去抚育一个后代,前提必须拥有极高的“父系确定性”。
“冠姓”本质上是一种公开的社会契约。 它向全社会和雄性个体宣告:“这个孩子是你的合法后代,配偶对你保持了忠贞。” 这种文化符号极大地降低了雄性的心理防御,成功**“诱骗”并激励了雄性将自己宝贵的生存资源源源不断地投资给这个孩子**。得到父亲资源支持的孩子,其存活率和未来的生育率都会显著上升。2. 农业社会中的“资源垄断”与“基因传递”
在人类长达数百万年的狩猎采集时代,人类并没有稳定的姓氏。但在约一万年前进入农业和畜牧业社会后,情况发生了根本性的变化。
- 资源可垄断化: 土地、牲口、财富变成了可以累积并被垄断的资源。在体力竞争占优势的农业社会,男性逐渐成为了这些资源的主要控制者。
- 最大化包容性适应度(Inclusive Fitness): 一个拥有大量土地和财富的男性,如何确保这些资源在自己死后,能最大化地帮助自己的基因在后代中扩散?
- 宗族与姓氏的作用: 通过“父系冠姓”建立起的继承顺序,确保了男性的巨额财富能精准地传递给拥有自己 50% 基因的后代(儿子),而不是便宜了外人。这种通过“文化符号(姓氏)”锚定“财富(生存资源)”传递的机制,极大地增强了该家族后代在饥荒、战争中的生存优势。
3. “Y染色体”与“姓氏”的完美重合:高效的亲属识别与结盟
从遗传学角度看,人类有一条独特的染色体——Y染色体,它是由父亲严格地、不经过重组地单向传递给儿子的。
- 天然的生物学重合: 父系宗族的“姓氏传递”路径,在绝大多数时候与Y染色体的传递路径完全重合。
- 文化绿胡子效应(Green-beard effect): 演化生物学中有一个概念叫“绿胡子效应”,指生物通过某种外在特征识别并帮助与自己拥有相同基因的亲属。在大型人类社会中,仅靠长相很难辨别远亲。
- 姓氏作为“文化绿胡子”: 姓氏和宗族观念成了最廉价、最高效的“亲属识别标签”。一个村庄或部落里,拥有相同姓氏的男性,大概率在 Y 染色体上具有高度的同源性。
- 演化优势: 这使得原本毫无社会关系的人,能够迅速因为“同姓/同宗”建立起超越血缘关系的信任。在生存资源争夺、抵御外敌和部落战争中,能够组织起成百上千名“同姓男性”共同战斗的父系宗族,其战斗力和生存概率,远远压倒了松散的无宗族群体。
反例的佐证:为什么没有形成普遍的“母系冠姓权”?
世界上确实存在过母系社会(如中国摩梭人的“走婚制”),但它们为什么没有成为全球主流?
- 在母系社会中,由于缺乏严格的一夫一妻制,父系确定性极低。
- 此时,男性的演化策略会发生转移:既然我无法确定妻子生的孩子是不是我的,但我 100% 确定我亲姐姐/妹妹的孩子(外甥)带有我的基因(约 25% 亲缘相关性)。
- 因此在母系社会中,男性不投资自己的“子女”,而是转去抚育自己的“外甥”。
- 但是,投资子女(亲缘度 50%)的基因回报率,天然两倍于投资外甥(亲缘度 25%)。
- 只要一旦具备了“能够保障父系确定性(一夫一妻/冠姓约束)”和“雄性可垄断资源”的生态条件,父系宗族策略的基因增殖效率就会以绝对的数学优势,迅速在演化竞争中淘汰母系策略。
总结
“姓氏”虽然只是写在纸上的名字,但它是人类社会演化出的一种高超的生物学管理工具。
它在文化上模拟了 Y 染色体的遗传路线,以极低的成本,换取了雄性最慷慨的抚育资源(解决了父系不确定性),并组建了坚固的雄性同盟(解决了群体生存竞争)。这就是为什么“大家长式的宗族观念”和“冠姓权”虽然在现代社会常被讨论和反思,但在历史长河中,它确实凭借其巨大的生物学和资源积累优势,成为了统治性的社会范式。
后代性别比例的策略
假定在上面提到的海象中出现了一个突变基因,而该突变基因有使父母所生的孩子大部分是女儿这种趋势。由于种群内不缺少雄性个体,因此不存在女儿寻找配偶的困难,制造女儿的基因从而能够散布开来。这样,种群内的性比率也就开始向雌性个体过剩转变。从物种利益的观点出发,这种情况不会发生问题。我们已经讲过,因为只要有几个雄性个体就足以提供一大批过剩的雌性个体所需要的精子,因此,从表面上看,我们可以认为,制造女儿的基因不断地扩散,直到性比率达到极度不平衡的程度,即剩下的少数几个雄性个体搞得筋疲力尽才能勉强应付。但是,试想那些生儿子的为数不多的父母,它们要享有多么巨大的遗传优势!凡是生育一个儿子的个体,就会有极大的机会成为几百只海象的祖父或祖母。只生女儿的个体能确保几个外孙、外孙女是无疑的,但同那些专事生儿子的个体所拥有的那种遗传上蔚为壮观的前景相比,就要大为相形见绌了。因此,生儿子的基因往往会变得多起来,而性比率的钟摆就又会摆回来。
为简便起见,我以钟摆的摆动来说明问题。实际上,钟摆绝不会向雌性占绝对优势的方向摆动那样大的幅度。因为性比率一旦出现不平衡,生儿子的这股自然选择压力就会开始把钟摆推回去。生育同等数目的儿女的策略是一种进化稳定策略,就是说,偏离这一策略的基因都要遭受净损失。
我的论述是以儿子的数目对女儿的数目为根据的,目的是为了使其简单易懂。但严格说来,应该根据亲代投资的理论进行解释,就是说以前面一章我们曾讨论过的方法,按亲代一方必须提供的所有食物和其他资源来进行计算。亲代对儿子和女儿的投资应该均等。在一般情况下,这意味着他们所生的儿子和女儿数目应该相等。但是,假如对儿子和女儿的资源投资额不均等的话,那么性比率出现同样程度的不均衡在进化上可以是稳定的。就海象而言,生女儿同生儿子的比例是3∶1,而对每个儿子投资的食物和其他资源却三倍于每个女儿,借以使每个儿子成为超群的雄性,这种策略可能是稳定的。把更多的食物投资在儿子身上,使他既大又强壮,亲代就可能使之有更多的机会赢得“妻妾”这个最高奖赏。但这是一个特殊的例子。通常的情况是,在每个儿子身上的投资同在每个女儿身上的投资数量大致相等,而性比率从数量上说一般也是1∶1。
这里的进化稳定策略 ESS 是: 亲代对儿子和女儿的整体投资应该均等.
所以两个性别中每个个体得到的投资比例与两个性别的个数成反比.
雌性面对的被抛弃风险更大
让我们再来探讨一下在本章开始时我们提到的那一对配偶。作为自私的机器,配偶双方都“希望”儿子和女儿数目均等。在这一点上他们是没有争议的。分歧在于,谁将承担抚养这些子女的主要责任。每一个个体都希望存活的子女越多越好。在任何一个子女身上,他或她投资得越少,他或她能够生育的子女就会越多。显而易见,实现这种愿望的方法是诱使你的性配偶在对每一个子女进行投资时付出比他或她理应付出的更多的资源,以便自己脱身同另外的配偶再生子女。这种策略是一种两性都向往的策略,不过对雌性来讲更难如愿以偿。由于她一开始就以其大而营养丰富的卵子付出了比雄性多的投资额,因此母亲从怀孕的时刻起,就对每个幼儿承担了比父亲更大的“义务”。幼儿一旦死亡,她会比父亲蒙受更大的损失。更确切地讲,为了把另一个新的幼儿抚养到同死去的幼儿同样大小,她今后必须比父亲进行更多的投资。如果她耍花招,让父亲照料幼儿,自己却同另一个雄性个体私奔,父亲也可以将抛弃幼儿作为报复手段,而父亲所蒙受的损失,相对来说要小。因此,至少在幼儿发育的早期,如果有这种抛弃行为发生的话,一般是父亲抛弃母亲和孩子,而不是相反。同样,我们可以推断出雌性个体对子女的投资多于雄性个体,这不仅在一开始,而且在子女整个发育期间都是如此。例如在哺乳动物中,在自己体内孕育胎儿的是雌性个体,幼儿降生之后,制造乳汁喂养幼儿的是雌性个体,抚养并保护幼儿的主要责任也落在雌性个体肩上。雌性个体受剥削,而这种剥削行为在进化上的主要基础是卵子比精子大。
面对被抛弃风险演化出的两种策略
我们已经分析了雌性个体一旦被遗弃,她可能采取的一些行动。但所有这些行动总有一点“亡羊补牢,犹未晚矣”之感。到底雌性个体有没有办法减轻由于其配偶首先对她进行剥削而造成损失呢?她手中握有一张王牌:她可以拒绝交配。她是被追求的对象,她掌握主动权。这是因为她的嫁妆是一个既大又富有营养的卵子。凡是能成功地与之交配的雄性个体就可为其后代获得一份丰富的食物储藏。雌性个体在交配之前,能够据此进行激烈的讨价还价。她一旦进行交配,就失去了手中的王牌——她把自己的卵子信托给了与之交配的雄性个体。激烈的讨价还价可能是一种很好的比喻,但我们都很清楚,实际情况并非如此。有没有任何相当于激烈讨价还价的某种实际形式能够借自然选择得以进化呢?我认为主要有两种可能性,一种为家庭幸福策略(the domestic-bliss strategy),一种为大丈夫策略(the he-man strategy)。
家庭幸福策略的最简单形式是:雌性个体对雄性个体先打量一番,试图事先发现其忠诚和眷恋家庭生活的迹象。在雄性个体的种群中,成为忠诚的丈夫的倾向必然存在程度上的差异。雌性个体如能预先辨别这种特征,她们可以选择具有这种品质的雄性个体,从而使自己受益。雌性个体要做到这点,方式之一是长时间地摆架子,忸怩作态。凡是没有耐心,等不及雌性个体最终答应与之交配的雄性个体大概不能成为忠诚的丈夫。雌性个体以坚持订婚期要长的方式,剔除了不诚心的求婚者,最后只同预先证明具有忠诚和持久的品质的雄性个体交配。雌性忸怩作态是动物中一种常见的现象,求爱或订婚时间拉得长也很普遍。我们讲过,订婚期长对雄性个体也有利,因为雄性个体有受骗上当、抚养其他雄性个体所生幼儿的危险。追求的仪式通常包括雄性个体在交配前所进行的重要投资。雌性个体可以等到雄性个体为其筑巢之后再答应与之交配,或者雄性个体必须喂养雌性个体以相当大量的食物。当然,从雌性个体的角度来讲,这是很好的事,但它同时也使人联想到家庭幸福策略的另一种可能形式。雌性个体先迫使雄性个体对它们的后代进行昂贵的投资,然后再交配,这样雄性个体在交配之后再抛弃对方,也就不会有好处了。会不会是这种情况呢?这种观点颇具说服力。雄性个体等待一个忸怩作态的雌性个体最终与之交配,是要付出一定代价的:它放弃了同其他雌性个体交配的机会,而且向该雌性个体求爱时要消耗它许多的时间和精力。到它终于得以同某一具体雌性个体交配时,它和这个雌性个体的关系已经非常“密切”。假使它知道今后它要接近的任何其他雌性个体也会以同样的方式进行拖延,然后才肯交配,那么,对它来说,遗弃该雌性个体的念头也就没有多大诱惑力了。
大丈夫策略:在采取这种策略的物种中,事实上,雌性动物对得不到孩子们的爸爸的帮助已不再计较,而把全部精力用于培育优质基因,于是它们再次把拒绝交配作为武器。它们不轻易和任何雄性个体交配,总是慎之又慎,精心挑选,然后才同意和选中的雄性个体交配。某些雄性个体确实比其他个体拥有更多的优质基因,这些基因有利于提高生育子女的机会。如果雌性动物能够根据各种外在的迹象判断哪些雄性动物拥有优质基因,它就能够使自己的基因和它们的优质基因相结合而从中获益。以赛艇桨手的例子来类比,一个雌性个体可以最大限度地减少它的基因由于与蹩脚的桨手搭档而受到连累的可能性。它可以为自己的基因精心挑选优秀的桨手作为合作者。一般来说,大多数雌性动物对哪些才是最理想的雄性配偶不会产生分歧,因为它们用以判断的依据都是一样的。结果,和雌性个体的大多数交配是由少数这几个幸运的雄性个体进行的。它们是能够愉快胜任的,因为它们给予每一个雌性个体的仅仅是一些廉价的精子而已。海象和极乐鸟大概也是这种情况。雌性动物只允许少数几只雄性动物坐享所有雄性动物都梦寐以求的特权——一种追求私利的策略所产生的特权,但雌性个体总是毫不含糊,成竹在胸,只允许最够格的雄性个体享有这种特权。
家庭幸福策略物种的演化
我曾在一篇论文中指出过,这里特里弗斯在推理方面有一个错误。他认为,预先投资本身会使该个体对未来的投资承担义务。这是一种荒谬的经济学思想。商人永远不会说:“我在协和式客机上(举例说)已经投资太多,现在把它丢弃实在不合算。”相反,他总是要问,即使他在这项生意中的投资数目已经很大,但为了减少损失,现在就放弃这项生意,这样做对他的未来是否有好处。同样,雌性个体迫使雄性个体在她身上进行大量投资,指望单单以此来阻止今后雄性个体最终抛弃她,这样做是徒劳的。这种形式的家庭幸福策略还要取决于一种进一步的重要假定:即雌性的大多数个体都愿意采取同样的做法。如果种群中有些雌性个体是放荡的,随时准备欢迎那些遗弃自己妻子的雄性个体,那么对抛弃自己妻子的雄性个体就会有利,不论他对她的子女的投资已经有多大。因此,这在很大程度上取决于大多数雌性个体的行为。如果我们可以根据雌性个体组成集团的方式来考虑问题的话,就不会存在问题了。但雌性个体组成的集团,同我们在第5章中讲到的鸽子集团相比较,其进化的可能性也不会更大些。我们必须寻找进化稳定策略。让我们采用史密斯用以分析进犯性对抗赛的方法,把它运用于性的问题上。这种情况要比鹰和鸽的例子稍微复杂一点。因为我们将有两种雌性策略和两种雄性策略。
同史密斯一样,我们将采用一些任意假定的数值,表示各种损失和利益。为了更加带有普遍性,也可以用代数符号来表示,但数字更容易理解。我们假定亲代个体每成功地抚养一个幼儿可得15个单位的遗传盈利,而每抚养一个幼儿所付出的代价,包括所有食物、照料幼儿花去的所有时间以及为幼儿承担的风险,是—20个单位。代价用负数表示,因为那是双亲的“支出”。在旷日持久的追求中所花费的时间也是负数,就以—3个单位来代表这种代价。
雌性个体交配以更多地散布自己基因的任何雄性个体,一想到必须还要杀死一条龙,就会打消这种念头。然而事实上雌性个体是不会将杀死一条龙或寻求圣杯这样专横的任务硬派给它们的求婚者的,因为如果有一个雌性个体对手,它指派的任务尽管困难程度相同,但对它以及它的子女却有更大的实用价值,那么它肯定会优越于那些充满浪漫情调、要求对方为爱情付出毫无意义的劳动的雌性个体。杀死一条龙或在达达尼尔海峡(Hellespont)中游泳也许比筑造一个巢穴更具浪漫色彩,但却远远没有后者实用。




- 忠诚催生放荡, 放荡催生薄情, 薄情催生忸怩, 忸怩催生忠诚. 最后在群体内达到动态平衡.
- 相比于派发诸如 “杀死一条龙” 这种抽象任务, 派发实实在在有利于后代生存的任务的雌性个体有更强的进化优势.
- 鸟类中建造一个巢是约束雄性个体的有效手段, 类比于人类婚俗中彩礼, 婚房等.
雄性需要在交配前为雌性提供弥补雌性生育成本的生存资源, 并且这个生存资源是实在且有利于后代的.
天道如此.
至此本章的内容可以归结为:动物界中各种不同的繁殖制度——一雌一雄、雌雄乱交、“妻妾”等等——都可以理解为雌雄两性间利害冲突所造成的现象。雌雄两性的个体都“想要”在其一生中最大限度地增加它们的全部繁殖成果。由于精子和卵子在大小和数量方面存在根本差别,雄性个体一般来说大多倾向于雌雄乱交,而缺乏对后代的关注。雌性个体有两种可供利用的对抗策略,我在前面曾称之为大丈夫策略和家庭幸福策略。一个物种的生态环境将决定其雌性个体倾向于采取其中的哪一种策略,同时也决定雄性个体如何做出反应。事实上,在大丈夫策略和家庭幸福策略之间还有许多中间策略。我们已经看到,有时候,做父亲的甚至比做母亲的更关心孩子们的生活。本书不打算描述某些具体动物物种的生活细节,因此我不准备讨论是什么促使一个物种倾向于某种繁殖制度而不倾向于另一种繁殖制度。我要探讨的是普遍地存在于雌雄两性之间的差异,并说明如何解释这些差异。因此我不想强调两性间差异不大的那些物种,因为一般来说,这些物种的雌性个体喜欢采取家庭幸福策略。
我们人类自己的社会有一个肯定与众不同的特点,这就是性的炫耀行为。我们已经看到,根据进化的理论,凡有不同性别个体存在的地方,喜欢炫耀的应该是男人,女人则喜欢朴实无华。在这一点上,现代的西方男人无疑是个例外。当然,有些男人衣饰鲜艳,有些女人衣饰朴素,这也是事实。但就大多数情况而言,在我们的社会里,像孔雀展示尾巴一样炫耀自己的毫无疑问是女人而不是男人。
面对这些事实,生物学家不得不感到疑惑,他观察到的社会是一个女人争夺男人而不是男人争夺女人的社会。在极乐鸟的例子里,我们认为雌鸟的色彩之所以朴素是因为它们不需要争夺雄鸟。雄鸟色彩鲜艳华丽,因为雌鸟供不应求,雌鸟可以对雄鸟百般挑剔,因为卵子这种资源比精子稀少。现代的西方男性到底发生了什么变化?男人果真成了被追求的性对象了吗?他们真的因女人供不应求而能对女人百般挑剔吗?如果情况果真如此,那又是为什么呢?
男人炫耀的是别的东西吧, 并没有体现在外貌上.
孔雀通过尾巴确立地位, 人类的方式更复杂.
而且人类更偏向家庭幸福策略, 双方的投资都很巨大, 所以存在双向的筛选.
生态环境如何决定两性配偶制度和交配策略
在进化生物学和行为生态学中,关于“生态环境如何决定两性配偶制度和交配策略”,确实存在一个经典的一般性结论。
这一理论最早由生态学家史蒂芬·埃姆伦(Stephen Emlen)和路易斯·奥林(Lewis Oring)于1977年提出(即著名的 Emlen-Oring 模型)。该模型指出:环境中的资源充裕度、资源的空间分布,以及后代对抚育的需求,共同决定了雌雄两性的进化策略。
为了便于理解,我们可以先将道金斯书中的“拟人化”策略,翻译为生态学中的行为模式:
- 家庭幸福策略(Domestic-Bliss Strategy) 单配制(Monogamy)与双亲共同抚育。雌性需要雄性的物质和劳力投入,雄性也选择留下来共同育雏。
- 大丈夫策略(He-Man Strategy) 一雄多雌制(Polygyny)或混交制(Promiscuity)。雌性不需要雄性的物质帮助,只筛选其优秀的基因;雄性不参与抚育,全力投入交配竞争。
以下是资源匮乏与资源充足等不同生态环境下,两性策略的演化方向:
一、 资源匮乏 / 恶劣生存环境:趋向于“家庭幸福策略”
当环境恶劣、食物资源匮乏或捕食压力极大时,后代的存活难度极高。
- 雌性的处境与策略:
- 在极端环境下,仅凭雌性单枪匹马,根本无法同时完成“寻找食物”、“看护巢穴”、“御敌”和“保暖”等繁重任务。如果雄性交配后直接溜走(薄情),后代几乎百分之百会夭折。
- 因此,雌性必须采取“家庭幸福策略”。她们会通过极长的求偶期、要求雄性筑巢、甚至要求雄性提前投喂食物(彩礼/婚前投资)来考验雄性。
- 雄性的反应与妥协:
- 由于雌性群体普遍高度“忸怩”,雄性极难随便找到一个“放荡”的雌性进行交配。
- 更重要的是,如果雄性选择遗弃配偶,它留在前妻那里的基因(后代)也会因为缺乏父亲的照顾而死亡。从自私基因的角度来看,“遗弃”的净收益降到了零。
- 因此,雄性不得不妥协,选择忠诚,并留下来承担大量的抚育工作。
- 典型代表: 绝大多数温带温性气候下的候鸟(如绝大多数雀形目鸟类)。由于育雏窗口期极短且昆虫资源紧俏,它们几乎都采取一夫一妻制,双亲共同拼命觅食。
二、 资源充足 / 优渥生存环境:趋向于“大丈夫策略”
当环境极度优渥、食物唾手可得(例如满地的落果或茂密的嫩草)时,后代的生存门槛变得很低。
- 雌性的处境与策略:
- 由于食物充足,雌性独自一人就能轻松喂饱自己和后代。此时,她不再需要雄性提供任何体力劳动或食物。
- 在这种情况下,雌性对雄性的筛选标准发生了质的变化:既然不需要你养家,那我就只看你的基因质量。雌性转而采取“大丈夫策略”,只与那些体格最壮、羽毛最艳、或歌声最响亮的雄性交配,以便让自己的后代遗传这些代表高免疫力、强适应性的“优质基因”。
- 雄性的反应与狂欢:
- 既然不需要承担抚育责任,雄性基因最大化传播的唯一途径就是“尽可能多地同其他雌性交配”。
- 雄性会将原本用于“养家糊口”的资源,全部转移到“军备竞赛”上:演化出巨大的体型、夸张的武器(如鹿角、海象牙)或者极度奢华的装饰(如孔雀的尾羽)。
- 典型代表: 栖息于热带雨林中的极乐鸟和孔雀,或者食物丰沛海岸边的海兽(如海象)。雌性可以轻松独立育雏,雄性则通过建立求偶场(Lek)或用武力垄断大批雌性,不提供任何父爱。
三、 另一个关键生态维度:资源的空间分布
除了“充足/匮乏”外,埃姆伦和奥林还强调了资源在空间上的分布特征(均匀 vs 集中),这对两性策略有决定性影响:
- 资源均匀分布(Dispersed Resources):
食物或水源零星分布在广阔的区域。雌性为了觅食不得不分散居住。在这种情况下,任何一个雄性都无法凭一己之力垄断多个雌性。雄性只能选择守着一个雌性,从而迫使系统向**“家庭幸福策略(单配制)”**靠拢。- 资源高度集中(Clumped Resources):
食物或水源集中在少数几个核心区域(如一片肥沃的草场或一口水源)。雌性会为了资源而高度聚集。这时,一个强壮的雄性可以通过武力霸占这个核心区域,从而轻松垄断所有到访的雌性(建立“后宫”)。这会极大地促进**“大丈夫策略(一雄多雌制)”**的演化。总结
生态环境要素 雌性的最适策略 雄性的反应 最终演化出的配偶制度 资源匮乏 / 育雏成本高 家庭幸福策略(极力筛选忠诚度,要求前期投资) 忠诚(留下来共同承担抚育) 单配制(一夫一妻,共同育雏) 资源充裕 / 雌性可独立育雏 大丈夫策略(放弃物质要求,只筛选优质基因) 薄情(最大化追求交配次数,发展炫耀性特征) 一雄多雌制 或 混交制(雌性独抚) 资源空间均匀分布 倾向于合作防御领地 无法垄断多个配偶,选择留下 单配制 资源空间高度集中 聚集在资源点 强壮个体垄断资源点,占有多个雌性 ** harem型一雄多雌制**(后宫制)
第10章 你为我搔痒,我就骑在你的头上
群居生活可以为一个自私个体带来各种各样的好处。在此,我不打算逐一罗列,只准备讲几个带有启发性的例子。其中我还要重提我曾在第1章里列举过的一些明显的利他行为的例子,因为我说过这些例子要留待以后再做解释,这样就必然要涉及对社会性昆虫的讨论。事实上,如果避而不谈社会性昆虫,对动物利他行为的论述就不可能全面。最后,在本章拉拉杂杂的内容中,我将谈到相互利他行为这个重要的概念,即“于人方便,于己方便”的原则。
Note
一、 群居生活的直接物理/生存益处
1. 鬣狗成群猎食(Hyenas hunting in packs)
- 现象: 鬣狗结成群体共同捕猎,捕获猎物后再共同分食。
- 自私基因的解释: 尽管捕获后需要分食,但成群捕猎能让它们捕捉到单只鬣狗绝对无法捕获的大型猎物。对参与其中的每个自私个体而言,分得的食物份额依然大于其独自捕猎的预期收益,因此群居在经济上是划算的。
2. 蜘蛛合作织造巨网(Spiders weaving communal webs)
- 现象: 某些种类的蜘蛛会共同合作,织造出一张巨大的共享蜘蛛网。
- 自私基因的解释: 类似于鬣狗捕猎,协同合作织网能极大地提高每个个体的捕食效率,个体从中获得的好处大于为此付出的合作代价。
3. 帝企鹅挤在一起(Emperor penguins huddling)
- 现象: 在极度寒冷的南极,帝企鹅会紧紧挤成一团。
- 自私基因的解释: 这是一种纯物理性的互利行为。挤在一起能显著减少每只企鹅暴露在冷空气中的身体表面积,从而帮助每只企鹅保存体温。
4. 鱼类成群游动(Fish schooling)
- 现象: 鱼类在水中成群游动时,后方的鱼会与前方的鱼保持一定的倾斜角度。
- 自私基因的解释: 物理流体动力学益处。后方的鱼可以利用前方鱼游动时激起的湍流来减少自身的阻力,从而节省体能。
5. 鸟类组成 V 字形飞行(Birds flying in V-formation)
- 现象: 候鸟迁徙时常排成 V 字形,并且会轮流担任飞在最前方的“领航员”。
- 自私基因的解释: 气流动力学益处。飞在后方的鸟可以利用前方鸟制造的气流减轻空气阻力。由于最前方的领航鸟处于最吃力的不利地位,它们通过轮流带头的方式来分担代价。这是一种延迟的相互利他行为(于人方便,于己方便)。
二、 避免被捕食的自私策略
6. 受到追捕的兽群挤成一团(Hamilton’s “Geometry for the Selfish Herd”)
- 现象: 当捕食者出现时,原本分散的动物会迅速向中心聚拢,紧紧挤成一团逃命。
- 自私基因的解释: 绝对的自私行为(无合作)。每只动物周围都有一个最容易被捕食的“危险区”,处于边缘的个体最危险。为了缩小自己的危险区,每只动物都拼命往群体中心挤,把其他个体挤到边缘。这种纯粹自私的动机导致了兽群在客观上“聚集成团”。
7. 鸟类的警报声(Bird alarm calls)
- 现象: 当发现老鹰等捕食者时,小鸟会发出高频的警报声。这种叫声物理特征特殊,捕食者极难定位声源。
- 自私基因的解释: 针对警报声的演化,书中给出了三种不互相排斥的解释:
- 解释 A(亲属选择): 如果鸟群中包含其近亲,警报声虽然对发出者有微小风险,但能拯救大量携带相同基因的亲属,使该基因在基因库中兴旺。
- 解释 B(凯维理论 - 针对伪装躲藏的鸟): 如果发现危险的小鸟独自蹲伏不动,而同伴继续活动喧闹,依然会把捕食者引到附近。因此,它发出警告让全体保持安静,是为了降低自己被同伴连累的风险。
- 解释 C(绝对不要脱离队伍理论 - 针对飞走的鸟): 独自飞向树林躲避的孤鸟是捕食者的首选目标。为了能安全飞到树上,它必须发出警报驱使整个鸟群一同飞起,利用群体的掩护来保证自己的安全。
8. 汤姆森氏瞪羚的跳跃(Stotting in Gazelles)
- 现象: 当捕食者逼近时,瞪羚不仅不悄悄躲避,反而故意在捕食者面前极高地弹跳。
- 自私基因的解释(扎哈维理论): 这绝非利他行为,而是向捕食者发出的自私信号。 它在炫耀:“看!我能跳这么高,说明我身强体壮、极难捕捉。你别在我身上浪费精力了,去追我那些跳不高的同伴吧!”捕食者收到信号后,往往确实会放弃追击强壮的跳跃者,转而寻找体弱的个体。
三、 社会性昆虫的极端“利他”与性比例博弈
9. 蜜蜂的自杀性蜇刺(Suicide stinging in honeybees)
- 现象: 工蜂在蜇刺入侵者后,其毒针和内脏会滞留并拉断,导致自身死亡。
- 自私基因的解释: 工蜂是不育的(职虫)。它们没有自己的后代,其全部基因的复制只能通过协助母亲(蜂后)生育姐妹来完成。工蜂在功能上相当于多细胞生物体内的“体细胞”(如无繁殖能力的肌肉或肝脏细胞),它们的自杀性保护行为是为了保证整个“基因工厂”(蜂巢)的基因得以延续。
10. 蜜罐蚁吊在巢顶充当食品库(Honey-pot ants)
- 现象: 某些工蚁终生吊在巢顶不动,腹部胀大如灯泡,塞满食物供其他蚂蚁食用。
- 自私基因的解释: 同样是因为它们是不育的职虫。它们压抑了个体的独立性,充当集体的“公共胃”,以此高效地抚养携带相同基因的亲属。
11. 膜翅目昆虫(蚁、蜂)的性比例争斗(Normal colony vs. Slave-making colony)
- 现象:
- 在普通的蚂蚁巢穴中,对有生殖能力的雌蚁和雄蚁的投资比例(数量及体重折算)表现为 3:1。
- 但在“豢养奴隶”的蚂蚁物种中,该投资比例却表现为 1:1。
- 自私基因的解释:
- 膜翅目的特殊单双倍体遗传制: 雌性(职虫和女王)有双倍染色体,雄性由未受精卵发育而来只有单倍。这导致职虫(雌性)与其姐妹的亲缘关系指数高达 3/4,而与其兄弟只有 1/4。
- 利益冲突: 女王希望生儿育女比例为 1:1(因为她对儿女的亲缘关系都是 1/2);而职虫希望母亲多生姐妹,最适比例是 3:1。
- 普通蚁群(3:1): 职虫把持着托儿所的抚养实权,它们“耕耘”女王。在这场世代冲突中,职虫战胜了女王,将性比例控制在 3:1。
- 奴役蚁群(1:1): 专门捕掠奴隶的蚂蚁不干活,巢穴由被掳来的奴隶蚁照料。奴隶蚁与这些幼虫毫无亲缘关系,无法通过自然选择演化出破译“女王伪装卵子密码”的能力。因此,在这类蚁群中,女王拥有绝对操纵权,成功将性比例控制在她“希望”的 1:1。
四、 跨物种的互利共生(Symbiosis)
12. 阳伞蚁经营菌圃(Parasol ants farming fungi)
- 现象: 阳伞蚁(切叶蚁)采集大量树叶并嚼碎,在地下室堆肥种植特定的菌类,以成熟的菌类为食。
- 自私基因的解释: 双向互利共生。 树叶的纤维极难被蚂蚁直接消化,但菌类能高效分解树叶。蚂蚁通过“耕作”获得了可口、易消化的食物;作为回报,菌类得到了蚂蚁提供的优质肥料、悉心照料(除草、灭除竞争菌)和高效的增殖与传播。
13. 蚂蚁饲养并“挤奶”蚜虫(Ants milking aphids)
- 现象: 蚂蚁用触角抚摩蚜虫臀部,促使其排出甜美的“蜜汁”作为食物;同时,蚂蚁会保护蚜虫、甚至将蚜虫的卵带回巢穴妥善照顾。
- 自私基因的解释: 不对称技能的互补。 蚜虫天生拥有吮吸植物汁液的口器(获得高糖水分),但缺乏自卫能力;蚂蚁不擅长吸汁,但擅长战斗。促进“蚂蚁战斗保护”和“蚜虫顺从排蜜”的基因在各自的基因库中都获得了极大的进化优势。
14. 地衣(Lichen)
- 现象: 地衣看起来是一种单一植物,实际上是菌类和绿海藻相依为命的共生体。
- 自私基因的解释: 两者在物理和化学上紧密结合。菌类提供水分、无机盐和固定支持,海藻通过光合作用提供有机养分。双方付出的代价远小于从对方身上获得的生存利益。
15. 细胞内的线粒体(Mitochondria in cells)
- 现象: 动植物体内的每个细胞都含有线粒体,负责为细胞提供生命活动所需的能量。
- 自私基因的解释: 内共生学说(Endosymbiotic theory)。 线粒体在进化早期原本是独立的共生微生物,后来与原始细胞结合并再也无法分离。
- 作者的激进延伸观点: 我们体内的基因也可以被看作是一个庞大的“共生基因群体”;而病毒则可能是脱离了这种群体的、寻求直接通过空气等介质寄生传播的“叛逆基因”。
如果联系的双方,如结合成地衣的两方,在提供有利于对方的东西的同时接受对方提供的有利于自身的东西,那我们对于这种互利的联系的进化在理论上就很容易想象了。但如果一方施惠于另一方之后,另一方却迟迟不报答,那就要发生问题。这是因为对方在接受恩惠之后可能会变卦,到时拒不报答。这个问题的解决办法是耐人寻味的,值得我们详细探讨。我认为,用一个假设的例子来说明问题是最好的办法。
傻子, 骗子, 斤斤计较者
假设有一种非常令人厌恶的蜱寄生在某种小鸟身上,而这种蜱又带有某种危险的病菌,所以必须尽早消灭这些蜱。一般说来,小鸟用嘴梳理自己的羽毛时能够把蜱剔除掉,可是有一个鸟嘴达不到的地方——它的头顶。对我们人类来说这个问题很容易解决。一个个体可能接触不到自己的头顶,但请朋友代劳一下是毫不费事的。如果这个朋友以后也受到寄生虫的折磨,这时你就可以以德报德。事实上,在鸟类和哺乳动物中,相互梳理整饰羽毛的行为是十分普遍的。
这种情况立刻产生一种直观的意义。个体之间做出相互方便的安排是一种明智的办法。任何具有自觉预见能力的人都能看到这一点。但我们已经学会,要对那些凭直觉看起来明智的现象保持警觉。基因没有预见能力。对于相互帮助行为,或“相互利他行为”中,做好事与报答之间相隔一段时间这种现象,自私基因的理论能够解释吗?威廉斯在他1966年出版的书中扼要地讨论过这个问题,我在前面已经提到。他得出的结论和达尔文的一样,即延迟的相互利他行为在其个体能够相互识别并记忆的物种中是可以进化的。特里弗斯在1971年对这个问题做了进一步的探讨。但当他进行有关这方面的写作时,他还没有看到史密斯提出的有关进化稳定策略的概念。如果他那时已经看到的话,我估计他是会加以利用的,因为这个概念很自然地表达了他的思想。他提到“囚徒窘境”——博弈论中一个人们特别喜爱的难题,这说明他当时的思路和史密斯的已不谋而合。
假设B头上有一只寄生虫,A为它剔除掉。不久以后,A头上也有了寄生虫,A当然去找B,希望B也为它剔除掉,作为报答。结果B嗤之以鼻,掉头就走。B是个骗子,这种骗子接受了别人的恩惠,但不感恩图报,或者即使有所报答,但做得也不够。和不分青红皂白的利他行为者相比,骗子的收获要大,因为它不花任何代价。当然,别人为我剔除掉危险的寄生虫是件大好事,而我为别人梳理整饰一下头部只不过是小事一桩,但毕竟也要付出一些代价,还是要花费一些宝贵的精力和时间的。
假设种群中的个体采取两种策略中的任何一种。和史密斯所做的分析一样,我们所说的策略不是指有意识的策略,而是指由基因安排的无意识的行为程序。我们姑且把这两种策略分别称为傻瓜和骗子。傻瓜为所有人梳理整饰头部,不问对象,只要对方需要。骗子接受傻瓜的利他行为,但却不为别人梳理整饰头部,即使别人以前为它整饰过也不报答。像鹰和鸽的例子那样,我们随意决定一些计算得失的分数,至于准确的价值是多少,那是无关紧要的,只要被整饰者得到的好处大于整饰者花费的代价就行。在寄生虫猖獗的情况下,一个傻瓜种群中的任何一个傻瓜都可以指望别人为它整饰的次数和它为别人整饰的次数大约相等。因此,在傻瓜种群中,任何一个傻瓜的平均得分是正数。事实上,这些傻瓜都干得很出色,傻瓜这个称号看来似乎对它们不太适合。现在假设种群中出现了一个骗子。由于它是唯一的骗子,它可以指望别人都为它效劳,而它从不报答别人,它的平均得分因而比任何一个傻瓜都高。骗子基因在种群中开始扩散开来,傻瓜基因很快就要被挤掉。这是因为骗子总归胜过傻瓜,不管它们在种群中的比例如何。譬如说,种群里傻瓜和骗子各占一半,在这样的种群里,傻瓜和骗子的平均得分都低于全部由傻瓜组成的种群里任何一个个体。不过,骗子的境遇还是比傻瓜好些,因为骗子只管捞好处而从不付出任何代价,不同的只是这些好处有时多些,有时少些而已。当种群中骗子所占的比例达到90%时,所有个体的平均得分变得很低:不管骗子也好,傻瓜也好,它们很多都因患蜱所带来的传染病而死亡。即使是这样,骗子还是比傻瓜合算。哪怕整个种群濒于灭绝,傻瓜的情况也永远不会比骗子好。因此,如果我们考虑的只限于这两种策略,没有什么东西能够阻止傻瓜的灭绝,而且整个种群大概也难逃覆灭的厄运。
现在让我们假设还有第三种被称为斤斤计较者的策略。斤斤计较者愿意为没有打过交道的个体整饰,而且为它整饰过的个体,它更不忘记报答。可是哪个骗了它,它就要牢记在心,以后不肯再为这个骗子服务。在由斤斤计较者和傻瓜组成的种群中,前者和后者混在一起,难以分辨。两者都为别人做好事,两者的平均得分都同样高。在一个骗子占多数的种群中,一个孤单的斤斤计较者不能取得多大的成功。它会花掉很大的精力去为它遇到的大多数个体整饰一番——由于它愿意为从未打过交道的个体服务,它要等到它为每一个个体都服务过一次才能罢休。因为除它以外都是骗子,因此没有谁愿意为它服务,它也不会上第二次当。如果斤斤计较者少于骗子,斤斤计较者的基因就要灭绝。可是,斤斤计较者一旦能够使自己的队伍扩大到一定的比例,它们遇到自己人的机会就越来越大,甚至足以抵消它们为骗子效劳而浪费掉的精力。在达到这个临界比例之后,它们的平均得分就比骗子高,从而加速骗子的灭亡。在骗子尚未全部灭绝之前,它们灭亡的速度会缓慢下来,在一个相当长的时期内成为少数派。因为对已经为数很少的骗子来说,它们再度碰上同一个斤斤计较者的机会很小。因此,这个种群中对某一个骗子怀恨在心的个体是不多的。
我在描述这几种策略时好像给人以这样的印象:凭直觉就可以预见到情况会如何发展。其实,这一切并不是如此显而易见的。为了避免出差错,我在计算机上模拟了整个事物发展的过程,证实这种直觉是正确的。斤斤计较的策略被证明是一种进化稳定策略,斤斤计较者优越于骗子或傻瓜,因为在斤斤计较者占多数的种群中,骗子或傻瓜都难以逞强。不过骗子也是ESS,因为在骗子占多数的种群中,斤斤计较者或傻瓜也难以逞强。一个种群可以处于这两个ESS中的任何一个状态。在较长的一个时期内,种群中的这两个ESS可能交替取得优势。按照得分的确切价值——用于模拟的假定价值当然是随意决定的——这两种稳定状态中的一种具有一个较大的“引力区”,因此这种稳定状态易于实现。值得注意的是,尽管一个骗子的种群可能比一个斤斤计较者的种群更易于灭绝,但这并不影响前者作为ESS的地位。如果一个种群所处的ESS地位最终还是驱使它走上灭绝的道路,那么抱歉得很,它舍此别无他途。
观看计算机进行模拟是很有意思的。模拟开始时傻瓜占大多数,斤斤计较者占少数,但正好在临界频率之上;骗子也属少数,与斤斤计较者的比例相仿。骗子对傻瓜进行的无情剥削首先在傻瓜种群中触发了剧烈的崩溃。骗子激增,随着最后一个傻瓜的死去而达到高峰。但骗子还要应付斤斤计较者。在傻瓜急剧减少时,斤斤计较者在日益取得优势的骗子的打击下也缓慢地减少,但仍能勉强地维持下去。在最后一个傻瓜死去之后,骗子不再能够跟以前一样那么随心所欲地进行自私的剥削。斤斤计较者在抗拒骗子剥削的情况下开始缓慢地增加,并逐渐取得稳步上升的势头。接着斤斤计较者突然激增,骗子从此处于劣势并逐渐接近灭绝的边缘。由于处于少数派的有利地位时受到斤斤计较者怀恨的机会相对地减少,骗子得以苟延残喘。不过,骗子的覆灭是不可挽回的,它们最终将慢慢地相继死去,留下斤斤计较者独占整个种群。说起来似乎有点自相矛盾,在最初阶段,傻瓜的存在实际上威胁到斤斤计较者的生存,因为傻瓜的存在带来了骗子的短暂繁荣。
又一个很有启发性的例子, 当斤斤计较者的数量能达到一个阈值, 群体还是有救的, 慢慢的群体会变成绝大多数斤斤计较者加少量的骗子. 但如果骗子占了上风, 那群体只有灭绝的份了, 尽管利己主义能为自己谋得一时私利, 但最终会因为自己的基因多了起来而导致整个群体的败亡.
事实上, 如果考虑维系 “斤斤计较” 这一系统的成本, 比如记忆力, 判断力, 认知成本等等, 傻子也会有存在的空间. 在全是斤斤计较者的群体中, 傻子因为不需要支付成本, 分数会略微高于斤斤计较者.
所以一个稳定的群体一定是斤斤计较者占大头, 傻子和骗子占小头的, 三者会达到动态平衡.
天道
这本书在不同的章节讨论了很多不同场景下的生存策略, 以及它们之间的相互博弈, 转化的作用关系.
社会运转中涉及相当多的个体之间的交互行为, 合作 / 竞争 / 互惠等等场景.
这本书先前提到的鹰与鸽子的竞争场景, 上面第10章讲的鸟类的互助场景, 加上人生独白中提到的合作博弈实验的合作场景.
社会真实的互动行为不止这些, 而且也复杂许多, 但我们能否从中窥见一种普遍的, 稳定的, 具备优越性的策略呢? 我想斗胆探讨一下这个问题.
互惠场景下的 斤斤计较者策略 和鹰与鸽子竞争场景部分提到的 还击策略 是对应的, 也对应于计算机程序合作博弈实验中的 一报还一报策略, 这些策略在各自的语境下都有各自的优越性, 要么是进化稳定, 要么干脆是最优的.
而这些策略在行动准则上都有一个共性, 可以这样简单的总结: 心向善, 行如镜.
- 心向善: 从不主动做坏事.
- 行如镜: 如果对方主动做坏事, 自己也跟着做坏事报复它.
| 场景 / ESS | 心向善 | 行如镜 | 垃圾 | 傻子 |
|---|---|---|---|---|
| 互惠场景 / 斤斤计较者 | 对于陌生鸟的求助, 总是会帮忙. | 拒绝帮助欺骗过自己的鸟. | 纯骗子. | 无条件帮助所有鸟. |
| 合作场景 / 一报还一报 | 从不主动背叛. | 复制合作者上一轮的行为. | 纯背叛者. | 无条件合作者. |
| 竞争场景 / 还击策略 | 从不主动发起攻击. | 如果对方攻击就还手. | 鹰. | 鸽子. |
有锋芒的善良符合道德且进化稳定.
也许是因为进化稳定所以符合道德, 也许是因为符合道德所以进化稳定, 这不重要.
它的优势是很明显的: 保证群体整体利益的情况下提高垃圾基因剥削的成本.
垃圾基因指极致的利己主义, 它们纯粹损害群体利益而不肯回报.
这种基因一旦多了起来, 群体将不可避免的走向败亡.
这类博弈场景都有一个临界值, 垃圾的占比一旦越过这个临界值, 群体也就完蛋了.
不同策略是会相互转化的, 在骗子横行的环境里, 只有骗子才能很好地生存下去, 傻子或是斤斤计较者为了自保, 也会倾向于像骗子转化.
斤斤计较者其实就能继续细分, 比如分成会主动帮助的和只给帮过自己的鸟帮忙的.
社会风气一旦败坏, 想要恢复可就难了.
PS: 竞争场景中不存在这样的灭绝陷阱, 这个博弈形式和上面两个有所区分.
鹰是可以被鸽子剥削的, 所以从 “致使群体灭亡” 的角度, 它并不是垃圾基因. 如果从道德上区分, 这个场景真正的垃圾应该是恶棍 / 恃强凌弱策略.
我想任何目光长远的人, 应该都会认同 “心向善, 行如镜” 的行动准则.
如果处在这样的灭绝陷阱里, 那死便死了吧, 反正这个群体已经烂透了, 灭亡是迟早的事.
斤斤计较系统的成本催生傻子, 傻子催生骗子, 骗子催生斤斤计较的系统.
如果考虑维持报复系统所需要的成本, 那么使得群体利益最大化的唯一解只有是一群傻子.
影视作品里的很多惹人喜欢的角色多少都有点傻子的特性, 这也是我们喜欢这类角色的原因, 因为他们是利他的, 可被剥削的. 不管是傻子, 骗子, 还是斤斤计较者, 都会 “喜欢” 这样的角色.
一群傻子还是有点难的, 不过在局部的, 片面的团体中, 少量的傻子还是相对容易达成的.
这时候就需要一些大智若愚的智慧了.
查理芒格教导我们要努力寻找这样可以互相信任的人际网络, 也就是这个道理.
所以在亲密关系里, 找到一个值得的人, 然后尽量安心地当个傻子吧!
Note
一、 斤斤计较系统的“成本”是什么?
在《自私的基因》所处的生物学背景中,“斤斤计较者”为了防止被剥削,需要支付昂贵的生理与心智成本:
- 记忆成本: 记住每一个相遇个体的独特面部特征或气味,以便下次辨认。
- 认知负荷: 随时在大脑里更新“记账簿”,记录每一次互动(谁帮我抓了痒,我帮谁抓了,谁上次逃单了)。
- 决策成本: 每次遇到新个体时,都要在脑海中评估、检索历史记录并做出“帮不帮”的抉择。
映射到人际关系/社会关系/亲密关系中,这个成本表现为:
- 心理防御与情感监视成本(俗称“心累”):
在关系里永远在默默“记账”和盘算彼此的得失(“上次我请他吃了100元的饭,这次他只请我喝了15元的咖啡,我是不是亏了?”、“上周我洗了三次碗,她只洗了一次,我是不是被剥削了?”)。这种持续的提防和得失计算,会消耗巨额的心理能量。- 程序与契约成本(法律、条约与程序):
芒格曾说过一句极为尖锐的话:“如果你拟定的结婚合同有47页纸,我的建议是你不要结婚。” 详细的合同、繁琐的审批、严格的防备性规定(如查手机、频繁定位、要求对方秒回以证明忠诚),都是人类为了对付潜在的“骗子”而支付的“斤斤计较成本”。你花在防御背叛上的精力,远超过了享受关系本身的精力。- 信任红利的完全丧失:
由于缺乏互信,每一笔合作都需要付出巨大的检验代价。
二、 为什么小团体“少量的傻子”更容易达成?
“傻子”(无条件利他、不设防的老实人)在宏观的大社会里极难存活,因为大社会是匿名、流动的,骗子榨取完一个傻子就可以溜之大吉,不付出任何代价。
但在高频、透明、规模受限的小团体中,“傻子”不仅能活下来,还会成为最受欢迎、最稳定的核心。这是因为小团体具有天然的保护效应:
- 高频且重复的博弈(Repeated Games): 小团体里的人天天见面,不是“一锤子买卖”。
- 低廉的声誉监督机制(外置的大脑记忆): 在一个小圈子里,不需要每个人都花精力去“记账”。“八卦”和“闲聊”扮演了共享数据库的角色。只要有人扮演“骗子”欺负了“傻子”,这个消息会在几小时内传遍圈子,骗子会被瞬间打上标签。
- 极高的背叛代价: 小圈子里背叛一个人的代价是“彻底社会性死亡”和“被开除出圈”。
- 无压力的“装傻”环境: 因为背叛代价太高,圈子里极少出现骗子。在这种极度安全的环境下,每一个“斤斤计较者”都可以卸下防御,安全地转型为“傻子”(大度、不计较、不设防),因为他们知道自己不会被毁灭。
三、 这对与人相处、小团体管理、两性亲密关系的启发
💡 启发一:与人相处 —— 展现“大智若愚”的低成本社交
- 主动释放“可被剥削”的善意:
在人际交往初期,不要表现得太精明和戒备。主动扮演一个稍微有点“傻气”、愿意先付出一点小利(主动请客、主动帮忙、不计较细节)的合作者。这是在向外界释放最强烈的信号——“我是个安全的合作者”。- 守住“雷霆还击”的底线:
“大智若愚”的精髓在于:平时像个傻子,动起手来像只鹰。 平时不计较小钱、小事,不花心思防人(节省了斤斤计较的成本)。但只要通过低成本的试探,发现对方是一个贪得无厌、抢占功劳、背后捅刀的“纯骗子”,立刻启动无情的“还击者”策略,一秒切断所有联系(绝交、拉黑),绝不给其第二次剥削的机会。这是以极低的精神内耗,筛选出最高质量的朋友圈。💡 启发二:小团体(团队管理) —— 追求“值得信赖的无缝信任网”
- 严格控制团队规模,小就是美:
芒格指出, Mayo Clinic(梅奥医学中心)的手术室就是无缝信任网的典范——医生和护士之间不需要复杂的程序,只有百分之百可靠的人在互相信任。在小团队(如创业初期、研究小组)里,应尽量避免考勤日报、层层审批等“斤斤计较的管理成本”。- 一票否决的筛选制(零容忍骗子):
信任网络的致命弱点在于:只要混入一个“骗子”,为了防范他,剩下的“傻子”就不得不集体进化成“斤斤计较者”,整个团队的运行效率和信任网会瞬间坍塌。因此,团队管理者最重要的任务不是去制定繁琐的规章制度,而是一旦发现搭便车的、抢功的、挑拨离间的“骗子”,必须立刻、无情地将其清除出队伍,以保护剩下“傻子们”的合作生态。💡 启发三:两性亲密关系 —— 极简的“零内耗”爱情
- 亲密关系是仅有两个人的极限“小团体”:
如果你和伴侣在家里依然维持着“斤斤计较系统”(“今天我下班累了,为什么还要我做饭?”、“上个月我送了你包,为什么这个月你没送我等值的礼物?”),那这段关系在数学上就已经是一场高内耗的灾难了。- “傻子模式”是亲密关系的终极形态:
真正健康的爱情,是双方都在对方面前完全卸下了“斤斤计较”的防御面具,心安理得地做个不设防的“傻子”——不计较谁付出的多,谁付出的少,因为双方都笃信对方绝对不会剥削、伤害自己。- 用“高互信”取代“高契约”:
如果你和伴侣需要制定极其详尽的“规则、条例、惩罚协议”才能勉强相处,说明你们已经退化成了高成本的“斤斤计较者”。你应该警醒:你们是在维系爱情,还是在艰难地进行防御?在亲密关系里,爱是结果,而信任是能让你们在对方面前安全地做个“傻子”的唯一解药。
第11章 觅母:新的复制因子
但是难道我们一定要到遥远的宇宙去才能找到其他种类的复制因子,以及其他种类的随之而来的进化现象吗?我认为就在我们这个星球上,最近出现了一种新型的复制因子。它就在我们眼前,不过它还在幼年期,还在它的原始汤里笨拙地漂流着。但它正在推动进化的进程,速度之快令原来的因子望尘莫及。这种新汤就是人类文化的汤。我们需要为这个新的复制因子取一个名字。这个名字要能表达作为一种文化传播单位或模仿单位的概念。“mimeme”这个词出自一个恰当的希腊词词根,但我希望有一个单音节的词,听上去有点像“gene”(基因)。如果我把“mimeme”这个词缩短为meme(觅母),切望我的古典派朋友们多加包涵。我们既可以认为meme与memory(记忆)有关,也可以认为与法语Même(同样的)有关,如果这样能使某些人感到一点慰藉的话。这个词念起来应与“cream”合韵。
猫 meme, 俄罗斯 meme?
梗, 表情包?
…
曲调、概念、妙句、时装、制锅或建造拱廊的方式等都是觅母。正如基因通过精子或卵子从一个个体转移到另一个个体,从而在基因库中进行繁殖一样,觅母通过广义上可以称为模仿的过程从一个大脑转移到另一个大脑,从而在觅母库中进行繁殖。一个科学家如果听到或看到一个精彩的观点,会把这一观点传达给他的同事和学生,他写文章或讲学时也提及这个观点。如果这个观点得以传播,我们就可以说这个观点正在进行繁殖,从一些人的大脑散布到另一些人的大脑。正如我的同事汉弗莱(N.K.Humphrey)对本章初稿的内容进行概括时精辟地指出的那样:“觅母应该被看成一种有生命力的结构,这不仅仅是比喻的说法,而是有学术含义的。当你把一个有生命力的觅母移植到我的心田上时,事实上你把我的大脑变成了这个觅母的宿主,使之成为传播这个觅母的工具,就像病毒寄生于一个宿主细胞的遗传机制一样。这并非凭空说说而已,可以举个具体的例子,‘死后有灵的信念’这一觅母事实上能够变成物质,它作为世界各地人民的神经系统里的一种结构,千百万次地取得物质力量。”
从根本上说,我们试图以基因的优越性来解释生物现象是可取的做法,因为基因都能复制。原始汤分子一具备能够进行自身复制的条件,复制因子就开始繁盛了起来。30多亿年以来,DNA始终是我们这个世界上唯一值得一提的复制因子,但它不一定要永远享有这种垄断权。新型复制因子能够进行自我复制的条件一旦形成,这些新的复制因子必将开始活动,而且开创自己的崭新类型的进化进程。这种新进化发轫后,完全没有理由要从属于老的进化。原来基因选择的进化过程创造了大脑,从而为第一批觅母的出现准备了“汤”。能够进行自我复制的觅母一问世,它们自己所特有的那种类型的进化就开始了,而且速度要快得多。遗传进化的概念在我们生物学家的大脑里已根深蒂固,因此我们往往会忘记,遗传进化只不过是许多可能发生的进化现象之中的一种而已。
…
让我举一个具体的例子来说明问题。教义中有一点对强迫信徒遵守教规是非常有效的,那就是罪人遭受地狱火惩罚的威胁。很多小孩,甚至有些成年人相信,如果他们违抗神父的规定,他们死后要遭受可怕的折磨。这是一种恶劣透顶的骗取信仰的手段,它在整个中世纪,甚至直至今天,为人们带来心理上的极大痛苦。但这种手段非常有效。这种手段可能是一个受过深刻心理学训练,懂得怎样灌输宗教信仰的马基雅维利式的牧师经过深思熟虑的杰作。然而,我怀疑这些牧师是否有这样的聪明才智。更为可能的是,不具自觉意识的觅母由于具有成功基因所表现出的那种虚假的冷酷性而保证了自身的生存。地狱火的概念只不过是由于具有深远的心理影响而取得其固有的永恒性。它和上帝觅母联结在一起,因为两者互为补充,在觅母库中相互促进对方的生存。
我猜想,相互适应的觅母复合体和相互适应的基因复合体具有同样的进化方式。自然选择有利于那些能够为其自身利益而利用其文化环境的觅母。这个文化环境包括其他的觅母,它们也是被选择的对象。因此,觅母库逐渐取得一组进化上稳定的属性,这使得新的觅母难以入侵。
文化吗.
人类可能还有一种非凡的特征——表现真诚无私的利他行为的能力。我唯愿如此,不过我不准备就这一点进行任何形式的辩论,也不打算对这个特征是否可以归因于觅母的进化妄加猜测。我想要说明的一点是,即使我们着眼于阴暗面而假定人基本上是自私的,我们自觉的预见能力——在想象中模拟未来的能力——能够防止自己纵容盲目的复制因子干出那些最坏的、过分的自私行为。我们至少已经具备了精神上的力量去照顾我们的长期自私利益而不仅仅是短期自私利益。我们可以看到参加“鸽子集团”所能带来的长远利益,而且我们可以坐下来讨论用什么方法能够使这个集团取得成功。我们具备足够的力量去抗拒我们那些与生俱来的自私基因。在必要时,我们也可以抗拒那些灌输到我们头脑里的自私觅母。我们甚至可以讨论如何审慎地培植纯粹的、无私的利他主义——这种利他主义在自然界里是没有立足之地的,在整个世界历史上也是前所未有的。我们是作为基因机器而被建造的,是作为觅母机器而被培养的,但我们具备足够的力量去反对我们的缔造者。在这个世界上,只有我们,我们人类,能够反抗自私的复制因子的暴政。
?
布什, 左右脑怎么开始打架了.
你说基因的自私是一种拟人化的比喻, 为什么又反复地赋予它主观能动性呢.
第12章 好人终有好报
囚徒困境
“好人垫后。”——这句俗语似乎来自棒球界,不过有些权威人士声称它有其他内涵。美国生物学家加勒特·哈丁(Garrett Hardin)用这句俗语来总结“社会生物学”或者“自私的基因”,其中的贴切不言而喻。在达尔文主义中,“好人”是那些愿意自身付出代价,帮助种群中其他成员个体,以此使他们的基因传到下一代的“人”。这么看来,好人的数目注定要减少,善良在达尔文主义里终将灭亡。这里的“好人”还有另一种专有解释,和俗语中的含义相差并不远。但在这种解释里,好人则能“得好报”。在这一章节里,我将阐释这个相对乐观的结论。
想想第10章里的斤斤计较者。那些鸟儿显然以利他的方式互相帮助,但对那些曾经拒绝帮助他人的鸟,它们却怀恨在心,以牙还牙地拒绝给予帮助。比起傻瓜(那些无私奉献却遭遇剥削的个体)和骗子(那些互相无情剥削而共同毁灭的个体),斤斤计较者在种群中占优势,因为它们可以将更多基因传递给后代。斤斤计较者的故事表达了一个重要原则,罗伯特·特里弗斯将此称为“互惠利他理论”。在清洁工鱼(第10章)的例子里,互惠利他不仅局限于单个物种,还存在于所有共生关系中。类似的例子还有蚂蚁为它们的“奶牛”蚜虫挤“奶”(第10章)。当第10章写就时,美国政治科学家罗伯特·阿克塞尔罗德将互惠利他的概念延伸至更为激动人心的方向。阿克塞尔罗德曾与威廉·唐纳·汉密尔顿合作,后者的名字在这本书里已经出现无数次了。开篇已经暗示过,正是阿克塞尔罗德赋予了“好人”一个专有含义。
如同许多其他政治科学家、经济学家、数学家与心理学家一样,阿克塞尔罗德对“囚徒困境”这一简单的博弈游戏很感兴趣。这个游戏极其简单,但我知道许多聪明人完全误解了游戏,以为其复杂无比。不过,它的简单也带有欺骗性。图书馆里关于这个博弈衍生物的书籍多如牛毛。许多有影响力的人认为它是解决战略防御规划问题的钥匙,这个模型需被仔细研究,以阻止第三次世界大战的发生。而作为一个生物学家,我站在阿克塞尔罗德与汉密尔顿一边。许多野生动物和植物正以其演化进程,精确无误地进行着“囚徒困境”的博弈。
在其原始的人类版本中,“囚徒博弈”是这样的:一个“银行家”判定两位玩家的输赢,并付与赢家报酬。假设我们便是这两位玩家,当我们开始博弈时(虽然我们将看到,“对立”是我们最不应该做的),我们手中各有两张卡,分别为“合作”与“背叛”。我们各自选定一张牌,面朝下摆放在桌子上,这样我们都不知道对方的选择,也不会为对方选择所影响,这便等同于我们同时行动。然后我们等待“银行家”来翻牌。我们的输赢不仅取决于我们出的牌,还取决于对方打出的牌。其悬念在于:虽然我们清楚自己的出牌,却并不知道对方的出牌。我们都只能等“银行家”来揭晓结果。我们一共有2×2=4张牌,于是也便有4种可能的结果。为向这个游戏的发源地——北美致敬,我们以美元来表示这4种输赢结果。
结果1:我们俩都选择了“合作”。“银行家”给我们每个人300美元。这个不菲的总数是对相互合作的奖赏。结果2:我们俩都选择了“背叛”。“银行家”对每个人罚款10美元。这是对相互背叛的惩罚。结果3:你选择“合作”,我选择“背叛”。“银行家”付给我500美元(这是背叛的诱惑),罚了你(傻瓜)100美元。结果4:你选择“背叛”,我选择“合作”。“银行家”将背叛的诱惑付给了你,而罚了我这个傻瓜100美元。结果3与4明显互为镜像。一个玩家得到好处,则有另一个玩家将付出代价。在结果1与2里,我们俩得到相同的结果,而结果1对我们俩都有好处。这里金钱的具体数目并不要紧,重要的是这个博弈里“囚徒困境”结果的排列顺序:背叛的诱惑>相互合作的奖赏>相互背叛的惩罚>失败的代价。(严格来说,这个博弈还有另一个条件:背叛的诱惑与失败的代价的平均值不可高于相互合作的奖赏。我们将在后边附加条件里提到这个原因。)
那么,为什么这是一个“困境”?看看这张输赢状况的表格,想象一下我在与你博弈时脑海中盘旋着的想法。我知道你只有两张牌,“合作”或者“背叛”。让我们按次序来想想。如果你打出“背叛”(这表示我们将看向表格中的右边一列),我能打出最好的牌也只能是“背叛”。虽然我也将接受相互背叛的惩罚,但我知道,如果选择了“合作”,失败者的代价只会更高。而如果你选择了“合作”(看向左边一列),我最好的结果也只能是选择“背叛”。如果我们合作了,我们都能得到300美元;但如果我选择背叛,我将得到更多—500美元。这里的结论是:无论你选择哪张牌,我最好的选择是永远背叛。
在“囚徒困境”这个简单博弈里,没有任何方法可以达成信任。除非其中一方是一个虔诚的傻瓜,善良得根本不可能适应这个世界,这个博弈注定将以相互背叛、相互损伤告终。然而,这个博弈还有另一个版本:“重复博弈”的“囚徒困境”。这个“重复博弈”更为复杂,但复杂性里孕育着希望。“重复博弈”只是简单将上述博弈与同一个对手无限次重复。你我再次在“银行家”面前左右相对,再次拥有手中的两张牌——“合作”与“背叛”,我们再次各自打出一张牌,由“银行家”根据上述规则给出奖赏与惩罚。但这一次对弈不再是博弈的终结,我们捡起手中的牌,准备着下一轮。下一轮的游戏给予我们机会来重新建立信任与怀疑,实施对抗或和解,给予报复或宽恕。在这无限长的博弈里,我们最重要的任务是:赢了“银行家”,而不是对方。
计算机博弈论实验
一、 实验过程的三个阶段
阿克塞尔罗德通过计算机程序模拟,举办了三场性质不同的竞赛,用以寻找在重复博弈中的最优行为策略:
阶段 1:第一次循环赛(寻找强劲策略)
- 方法: 邀请博弈论专家提交了 14 个策略程序,加上 1 个“随机”策略作为基准,共 15 个策略。两两进行“循环赛”(包括自己与自己博弈),每个组合博弈 200 回合。
- 计分规则: 双方合作得 3 分(基准分 600 分),背叛单方得 5 分,双方背叛得 1 分,被背叛得 0 分。
- 结果: 加拿大心理学家阿纳托尔·拉波波特提交的**“针锋相对”(Tit-for-Tat, TFT)**策略胜出。其规则极简:第一回合合作,之后每一步都简单复制对手上一步的行动。
阶段 2:第二次循环赛(信息公开后的博弈)
- 方法: 共有 63 个策略参赛。参赛者事先获知了第一次比赛的结果以及对 TFT 策略的分析。参赛者因此分化为两派:一派提交了更温和宽容的策略,另一派则试图提交更狡猾的恶意策略来剥削老实人。
- 结果: TFT 再次蝉联冠军。 排名最前的 15 个策略中,除一个外全是“善意策略”(不主动背叛);排名最后的 15 个策略中,除一个外全是“恶意策略”。这证明了“好人可以胜出”。
阶段 3:演化模拟赛(寻找进化稳定策略)
- 方法: 模拟自然选择。使用第二次竞赛的 63 个策略作为第一代。博弈结束后,赢家不再获得积分,而是将分数转化为等比例的后代数量。经历 1000 代的演化迭代。
- 结果: 恶意策略(如“哈灵顿”)在早期因剥削过度宽容的老实人而短暂繁荣,但随着猎物被榨干灭绝,它们也因失去剥削对象而迅速灭绝。最终留存下来的,均是类似于 TFT 那样“善良且具备报复性”的策略。
二、 核心结论
1. 获胜策略(TFT)的三大生物学特征
阿克塞尔罗德和道金斯总结出,要在重复博弈的复杂生态中胜出,策略必须具备以下三个特质:
- 善良(Nice): 从不首先背叛,避免主动挑起内耗。
- 宽容(Forgiving): 记忆短暂。虽然对背叛会立刻进行对等报复,但只要对方重新选择合作,它就会立刻既往不咎,终止冤冤相报的恶性循环。
- 不嫉妒(Not Envious): 不以“战胜对手(比对手拿更多分)”为目的,而是致力于与对手精诚合作,共同向“银行家(自然环境)”索取绝对高分。
2. TFT 并不是严格意义上的 ESS(进化稳定策略)
- 在全是 TFT 的世界里,由于大家始终在合作,TFT 无法与“无条件合作”策略在行为上做出区分。
- 这导致“无条件合作”等策略可以无成本地漂变、混入种群。一旦无条件合作者数量变多,就会引来“永远背叛(AllD)”的入侵和毁灭。
- 因此,TFT 在数学上不是严格的 ESS,但它是一种高度近似的**“集体稳定策略”**。
3. “双稳态(Bi-stability)”与决胜点
- 系统存在两个主要稳定点:“永远背叛(AllD)”和“针锋相对(TFT)”。
- 如果一个群体已经被 AllD 主导,单一或少数的 TFT 很难通过随机遇到彼此来获取合作的高分,系统会被锁死在 AllD 的深渊中。
- 要让种群从 AllD 转换为 TFT,TFT 的数量必须跨越一个临界值,即**“决胜点”**。
三、 演化与现实启示
1. 亲属聚集(小团体)能够实现单向入侵
如果只靠“运气”或随机,稀少的 TFT 很难跨越决胜点。但自然界提供了一个天然的物理机制——“黏性”与亲属聚集:
- 因为生物地理上的黏性(倾向于留在出生地),亲属(兄弟姐妹、表亲)往往聚集在一起居住。
- 这些具有亲缘关系的个体在局部高频互动,使得 TFT 即使在全局数量极其稀少,也能在局部高频相遇、精诚合作,拿到
+3的合作高分。- 这种局部的繁荣会像火苗一样向外扩散,最终帮助 TFT 单向跨越决胜点,攻占被 AllD 统治的世界。
- 相反,“永远背叛”无法通过聚集获得任何好处,因为背叛者聚集只会加速互相伤害。
2. 人类“嫉妒”的直觉误区
阿克塞尔罗德指出,当心理学家用人类进行重复囚徒困境实验时,绝大多数人类都会本能地表现出“嫉妒”(即试图击败对手,让自己的得分高过对方)。这种零和博弈的直觉,导致人类在现实博弈中的实际收益往往远远低于理论上的合作最优解(基准分)。
零和博弈与非零和博弈
博弈理论家将博弈分为“零和”与“非零和”两种。“零和博弈”指一方的胜出即是对方的损失。棋类游戏便是一种“零和博弈”,因为博弈双方的目标是胜过对方,使对方产生损失。囚徒困境则是一种“非零和博弈”,在这里,“银行家”支付了金钱,博弈双方可以携手合作,一起笑到最后。这让我想起了莎士比亚写过的一句精彩的台词:“我们要做的第一件事,就是把所有律师都先杀了。”——《亨利六世》
在所谓“民事争议”中,事实上经常有很大空间可以合作。一个看似“零和博弈”的争议也许只要加入少许善意,便可以转化为双方互利的“非零和博弈”。下面拿离婚作为例子。一段好的婚姻明显是一个“非零和博弈”,充满了互助合作的空间。即使它瓦解,夫妻依然可以继续合作,以“非零和博弈”来看待离婚,并从中得到好处。如果孩子抚养权的判决问题并不是一个足够劝服夫妻合作的理由,双方律师的高昂费用也许更有说服力,因为它将给家庭财政造成巨大创伤。那么,如果一对理性文明的夫妻从一开始便一起雇用同一个律师,这是不是更合理呢?
夫妻与律师的博弈
这段话的核心思想是:利用博弈论中的“零和博弈”与“非零和博弈”概念,来揭示现代法律诉讼系统(以离婚官司为例)是如何扭曲人性,将原本可以合作共赢的社会关系强行转化为“双输”的对抗,并在此过程中让第三方(律师)渔翁得利的。
道金斯通过这个例子指出,许多看似是你死我活的“零和”冲突,只要加入合理的制度设计和善意,完全可以转化为互利的“非零和”合作。
以下是夫妻之间的博弈关系与律师之间的博弈关系在性质、逻辑和后果上的详细对比:
一、 夫妻之间的博弈关系
- 博弈性质:被迫的“零和博弈”(实际上最终演变为“负和博弈”)
- 背后的逻辑:
- 系统强行对立: 婚姻本是一个典型的“非零和博弈”(双方通过共同生活、分工协作实现双赢)。即使婚姻破裂,双方如果理性协商,依然可以通过非零和合作(如庭外和解、共同雇用一个律师)来最大化保留家庭财产、平稳过渡。
- 法律规则的扭曲: 现代法律(如英美法系)的职业规范禁止夫妻共用一个律师,强行将他们推入“史密斯诉史密斯”的对抗架构。
- 囚徒困境的绑架: 一旦进入法庭程序,双方律师会不断提出对方无法接受的苛刻条件。此时,夫妻任何一方如果选择“温和/鸽子策略”(不请好律师、大度退让),就会面临被对方彻底剥削的惨痛代价。因此,双方被迫选择“强硬/鹰策略”(各自雇大牌律师、死撕到底)。
- 后果:
夫妻双方本想通过打官司争夺财产(零和:我多拿1万,你就少拿1万)。但因为支付了极其高昂的律师费,家庭总资产被严重抽干。这场官司打完,夫妻双方都得到了极少的资源,成为了双输的“负和博弈”受害者。
二、 律师之间的博弈关系
- 博弈性质:隐性的“非零和合作博弈”(对律师群体而言是双赢)
- 背后的逻辑:
- 表面对抗,实质合作: 在法庭上,两名律师看起来是针锋相对的“对手”。但在经济利益上,他们是一根绳上的蚂蚱。
- 行业规范的默契: 律师行业无须刻意串通,其“独立执业、为客户争取最大利益”的职业规范本身,就是一种精密的合作工具。
- 制造并延长冲突以收费: 律师们通过撰写试探性的法律文书、打电话、打口水仗,每多走一个流程,计费账单就多加一笔。只要官司拖得足够久、冲突足够激烈,双方律师能收取的总费用(非零和的池子)就会越来越大。
- 吸血蝙蝠隐喻:
这就像吸血蝙蝠互相喂血一样。律师们并不需要有意识地去欺骗客户,法律系统和行业规则的自组织运行,自然而然地让他们达成了这种“专业剥削客户”的非零和合作。- 后果:
无论官司最后谁打赢,两边的律师都获得了丰厚的财务回报(双赢)。
三、 总结两者的区别与本质
比较维度 夫妻之间的博弈 律师之间的博弈 博弈关系 史密斯 诉 史密斯(夫妻对抗) 律师 A + 律师 B(共同剥削客户) 博弈类型 表面是零和(我赢你输),实质是负和(双输) 完美的非零和合作(双赢) 财富流向 财富从家庭流出,不断缩水 财富流入律师口袋,不断增加 驱动机制 被迫陷入“不背叛/不抵抗就会被毁灭”的防御深渊 系统的规则和计费模式自然诱导出的“行业默契” 道金斯的最终启示
道金斯写这一段,是为了将重复囚徒困境的理论映射到人类文明的设计中。
他认为,英国议会(下议院)和英美法庭一样,都是充斥着**“零和博弈心理”的对抗性场所。因为制度设计者(多为律师出身)习惯了“我赢你输”的二元对立思维,导致社会运行支付了太多不必要的“摩擦和内耗成本”**(也就是我们前面讨论过的“还击系统/计较系统成本”)。
如果决策者能多学一点博弈论,明白“非零和合作”的价值,就能通过修改法律(如允许庭外联合和解),引导人们放下武器,在不支付高昂中间人成本的前提下,达成更理性的合作。
我们该怎么做呢?莎士比亚的方法太过残酷,单单改变法律就简单多了。但大多数国会议员有法律背景,只有“零和博弈”心理。很难想象哪里存在比英国下议院更具对抗性的氛围了。(法庭至少还保持了辩论的斯文,因为律师们可以抱着“我博学的朋友将和我合作而笑到最后”的心理。)也许那些用心良苦的立法者和良心发现的律师需要学一点博弈论。只要律师以完全相反的方式工作,劝说顾客们放弃零和博弈的厮杀,就可以从庭外和解的非零和博弈中得到更多好处。
莎士比亚说的还是有些道理的.
其它相关的示例
理查德·道金斯列举了从人类社会到自然界、微生物界的多个博弈示例。这些例子共同论证了一个核心观点:在“未来的阴影很长(博弈次数多且终点不可知)”的“非零和博弈”中,善良、宽容、不嫉妒的“针锋相对”策略往往能自发演化出来,并促使整体兴旺。
以下是文中列举的所有示例的简短概括:
1. 1977年英格兰足球保级战
- 现象: 考文垂队与布里斯托队在比赛临近结束时战成 2-2 平局。此时传来竞争对手桑德兰队输球的消息,这意味着平局能让两队双双保级成功。随后,两队球员放弃进攻,只是互相传球消磨时间直到完场。
- 解释: 原本是你死我活的“零和博弈”(足球赛),在外界规则变化和第三方信息(桑德兰输球)的介入下,瞬间转化为“非零和博弈”。两队通过默契的合作(平局)击败了共同的“惩罚”(降级),实现了双赢。
2. 一战堑壕战中的“自己活,也让别人活”系统
- 现象: 英德两军在前线长期对峙期间,自发形成了不言而喻的默契:不朝正在散步的敌兵开枪、在固定时间朝固定空地开炮(仪式性开火)、甚至在圣诞节共同饮酒。一旦发生意外交火,开火方会主动道歉以防止报复升级。
- 解释: 长期对峙拉长了“未来的阴影”,且调防时间不可知,这构成了一个典型的重复囚徒困境。普通士兵为了生存,自发演化出了“针锋相对”的合作家族策略:不主动挑衅(善良),通过准时开炮展示报复能力(威慑),对意外伤害表示歉意以终止恶性循环(宽容)。
3. 人体常驻菌群与败血症
- 现象: 人体内的某些常驻菌群平时对宿主无害甚至有益,但在宿主遭受严重外伤濒死时,它们会突然发作,导致致命的败血症。
- 解释: 平时人体健康,“未来的阴影”很长(寄生菌可以活很久),双方选择长期非零和合作。一旦宿主受重伤,博弈可能即将结束。此时短期“背叛”(榨干宿主、疯狂繁殖)的诱惑大过了长期合作的奖赏,因此无意识的细菌演化出了在博弈末期发动致命袭击(背叛)的特征。
4. 无花果树与榕小蜂的共生
- 现象: 榕小蜂在无花果内产卵并为其授粉。如果榕小蜂“背叛”——只在花朵中产卵却不履行授粉职责,无花果树就会直接让这颗未成熟的果实脱落,导致其中的榕小蜂后代全部死亡。
- 解释: 这是一种无意识的、植物对动物的“针锋相对”式报复。无花果树通过消灭 cooperative 资源的手段,惩罚了榕小蜂的单方面剥削(背叛),以此维系两者的长期共生。
5. 雌雄同体海鲈鱼的性别交换
- 现象: 雌雄同体的海鲈鱼结成配偶后,会严格轮流扮演雌性(产卵,付出高成本)和雄性(提供精子,付出低成本)的角色。如果有一方在轮到自己时拒绝产卵,两者的配偶关系就会破裂。
- 解释: 制造卵子的成本远高于精子。为了防止对方只占便宜不出力(背叛),它们演化出了“针锋相对”策略:合作即轮流扮演雌性,一旦对方试图一直扮演雄性(背叛),就会遭到对方终止配偶关系或拒绝交配的惩罚。
6. 吸血蝙蝠的血液共享
- 现象: 没吸到血而面临饿死危险的蝙蝠,会获得同巢穴伙伴(甚至是无血缘关系的室友)反流吐出的血液救命;而来自其他巢穴的陌生蝙蝠极难获得这种帮助。
- 解释: 对饱食蝙蝠而言,少许血液的损失无关痛痒,但对濒死蝙蝠却是救命之恩,符合非零和博弈条件。蝙蝠群居在固定巢穴中(未来的阴影很长),并能互相识别。它们对“老朋友”采取合作态度,对无法提供互惠的“陌生人(潜在的骗子)”则拒绝提供帮助,以此防范剥削。
第13章 基因的延伸
自私基因的理论核心中有个矛盾很令人不安,这个矛盾存在于基因与生命的载体——生命体之间。一方面,我们已经得到一个漂亮的故事:独立的DNA复制因子如羚羊般灵活,它们自由奔放地世代相传,在一次性的生物容器中临时组合,不朽的双螺旋则不停改组演替,在形成终将腐朽的肉体时磨炼,最终走向各自的永恒。另一方面,如果我们只观察生命个体本身,每一个生命都是一台自成一体的仪器,它完美无缺,复杂精密,却又统一结合,组织紧密。生命体并非只是一个松散临时的基因组合所构成的产品。在精子与卵子即将开启一个新的基因混杂过程时,这些“交战”的基因载体并非刚刚认识彼此。生命体凭借专注的大脑协调着肢体与感觉器官进行合作,以完成各种生物目的。
作为载体,它的工作已臻极致。在本书的一些章节里,我们已经考虑过将个体生物看作一个载体,这个载体的任务是努力扩大传递基因的成功率。我们想象个体动物进行着复杂的思考,计算着各种行为的基因优势。但在另一些章节里,这些基础的理性思维则是从基因角度出发考虑的。如果失去了基因的角度,生命体便失去“关照”其繁衍成功率与亲属的理由,会转而考虑其他因素,比如它自身的寿命。
这两种对生命的思考方式之间的矛盾如何解决?我曾经在《延伸的表型》一书中尝试回答这个问题。这本书是我职业生涯中最高的成就,是我的骄傲与乐趣。本章节是该书几个主题的简要概括,但我更希望你们合上现在手中这本书,打开《延伸的表型》开始阅读。
NOTE
这是理查德·道金斯对其代表作《延伸的表型》(The Extended Phenotype)核心观点的简要概括,旨在解决自私基因理论中的一个核心矛盾:既然基因是自私且独立的复制因子,为什么它们会高度合作,组合成结构精密、浑然一体的“生命个体”(载体)?
道金斯通过引入**“延伸的表型”(The Extended Phenotype)**这一概念解答了这个问题。以下是该段论述的核心内容总结:
一、 核心概念:“延伸的表型”
传统的生物学定义中,基因的“表型”(Phenotype)仅限于它对其所居住的生物单个身体的作用(如眼睛颜色、骨骼结构)。
而道金斯提出,基因的表型不应局限于生物体的皮肤边界,而应该延伸到其对整个世界的作用。 只要是自然选择所偏爱的、有利于基因自身复制的性状,无论这个性状表现在无生命物体上,还是表现在另一个生物体上,都是该基因的“延伸表型”。
二、 延伸表型的三个层面与实例
道金斯通过由浅入深的实例,展现了基因跨越身体边界操纵外界的规律:
1. 基因对无生命物体的操纵
- 实例:石蚕蛾幼虫的石头房子(或蜘蛛网、海狸河坝)
- 现象: 石蚕蛾幼虫会用黏合剂将精心挑选的石头、树枝拼接成管状房屋保护自己。
- 解释: 房子的石块硬度和拼接角度,直接决定了幼虫的存活率。控制这一建房行为的基因,本质上就是“控制石头形状/硬度的基因”。房子的物理特征是石蚕蛾基因在体外的延伸表型。
2. 基因对其他生物身体的操纵(寄生与剥削)
- 实例 A:吸虫(扁虫)与蜗牛
- 现象: 被吸虫寄生的蜗牛会分泌出异常厚重的外壳。
- 解释: 吸虫的基因操纵了蜗牛的细胞,迫使蜗牛将原本用于繁殖的能量用来制造厚壳,以保护宿主(从而保护寄生其中的吸虫)。这层厚壳是吸虫基因的延伸表型。
- 实例 B:微孢子虫与面粉甲虫 / 蟹奴与螃蟹
- 现象: 微孢子虫合成保幼激素,让甲虫幼虫无法发育为成虫,而是长成巨型幼虫;蟹奴寄生于螃蟹,将其睾丸或卵巢去势,让螃蟹把能量用于喂肥寄生虫。
- 解释: 巨型的甲虫幼虫和被阉割的螃蟹,都是寄生生物(微孢子虫、蟹奴)为了自身基因的繁衍,利用其延伸表型对宿主身体进行操纵的结果。
3. 基因对其他生物行为的操纵(病毒与传染病)
- 实例:狂犬病毒与病犬 / 感冒病毒与人类
- 现象: 狂犬病毒使狗变得凶猛、爱撕咬并疯狂奔跑、口吐唾液;感冒病毒让人剧烈咳嗽、打喷嚏。
- 解释: 这些看似是“疾病症状”,实则是病毒为了寻找下一个宿主,通过其基因的延伸表型精准控制了宿主的中枢神经或生理机制。
三、 演化法则:何时合作?何时冲突?
道金斯指出,无论是宿主与寄生虫、细菌与昆虫,还是我们自身的染色体基因之间,决定它们是走向“合作共生”还是“对抗剥削”的根本演化机制,在于它们将基因传递给未来的出路(渠道)是否相同。
- 渠道不同 走向剥削与冲突:
如果寄生生物的基因不需要通过宿主的精子/卵子传递给下一代(如感冒病毒通过空气、吸虫通过复杂水体),它们就会肆无忌惮地损害、剥削宿主,以实现自身利益的最大化。- 渠道相同 走向合作与融合:
- 实例: 绿色水螅体内的水藻、豚草甲虫体内帮助刺破卵子的细菌,它们都必须通过宿主的卵子才能传递给后代。
- 解释: 既然双方共享唯一的未来出路,它们的命运和利益就完全绑定在一起了。寄生生物在演化上计算出的“最佳策略”就会与宿主高度一致。它们会停止寄生,开始精诚合作,甚至在千百年的演化中完全融入宿主细胞(如线粒体、叶绿体的起源),变得不可分割。
四、 总结:生命个体存在的真相
这个理论最终解释了“为什么会存在高度统一、精密运作的生命体(如人类)”:
我们体内的成千上万个常规基因之所以能够不自私打架、各司其职、高度合作地把我们这个“载体”建设得如此完美,仅仅是因为它们都共享着同一条唯一的出路——精子或卵子。
如果某个基因(如老鼠的 基因,或癌细胞、质粒、游离 DNA)找到了脱离这条常规出路的其他手段,它们也会立刻停止合作,转而表现得极度自私,甚至给整个生命体带来灭顶之灾。因此,生命个体并不是进化的终极追求,它只是所有共享同一条基因出路的复制因子们,为了共同的未来而妥协、合作所构建的一座“临时庇护所”。
Note
一、 跨越地理距离的“延伸表型”
基因对外部世界的操纵并不局限于身体表面,它可以跨越空间距离,在很远的地方产生表型作用。
1. 对无生命物理环境的超远距离改造:海狸的人工湖
- 现象: 海狸建造的大型河坝能够制造出方圆上百码的“人工湖”,用以防范天敌、运输树木。
- 解释: 这个人工湖就像海狸的牙齿和尾巴一样,是海狸体内“筑坝基因”的延伸表型。虽然它跨越了数百码的距离,但它同样受到自然选择的塑造。
2. 对其他生物神经系统的超远距离操纵:布谷鸟与养父母
- 现象: 体形娇小的养父母(如岩鹨)会不顾一切地拼命喂养体形庞大、完全不同种类的布谷鸟雏鸟。
- 解释(超级刺激/药瘾理论): 布谷鸟雏鸟的红色大嘴对养父母的神经系统而言是一种“超级刺激”。这就像一种强效的上瘾药物,甚至能隔空“施展魔法”,强行接管养父母的大脑,迫使其交出食物。
- 为什么宿主没有演化出抵抗力?——“生命与晚餐的原则”(The Life-Dinner Principle):
- 在两者的演化军备竞赛中,失败的代价是不对等的。
- 如果布谷鸟无法操纵宿主,它就会失去生命(死掉),基因彻底断绝。
- 如果宿主被布谷鸟操纵,它只是失去一顿晚餐(这一季无法繁殖),下个季度还有机会。
- 由于“活命”的选择压力远大于“晚餐”,自然选择赋予布谷鸟的“操纵武器”总是跑在宿主“抵抗武器”的前面。
二、 极端寄生与“化学意念控制”(社会性昆虫实例)
在昆虫世界中,基因跨越身体、操纵其他生物行为的现象达到了荒诞、惊人的地步:
- “弑君者”与“斩首者”蚂蚁(Bothriomyrmex): 寄生蚁后偷偷溜进宿主蚁巢,爬到宿主蚁后背上,安静地将其头颅慢慢砍下。接着,它释放化学信号“奴役”了毫无察觉的工蚁,让它们帮自己抚养后代,最终实现鸠占鹊巢。
- “意念控制”寄生蚁(Monomorium santschii): 这种寄生蚁后甚至不需要自己动手。它仅凭分泌出的某种极其阴险的化学“药水”(意念控制),就能驱使宿主工蚁发疯般地偏离天性,转去合谋杀死它们自己的亲生母亲(宿主蚁后)。
- 蝴蝶幼虫与蚂蚁保镖(Thisbe irenea): 蝴蝶幼虫通过肩膀上的喷嘴释放挥发性药水,给守卫的蚂蚁“下药”。被蛊惑的蚂蚁会变得极具攻击性、誓死保护幼虫,并进入“结合(上瘾)”状态,连续几天不离不弃。
三、 延伸表型的中心法则
基于上述所有超远距离的、跨越物种的操纵行为,道金斯总结出了**“延伸表型”的中心法则(The Central Theorem of the Extended Phenotype)**:
“动物的行为倾向于最大化指导此行为的基因的生存,无论这些基因是否在做出此行为的动物体内。”
这颠覆了传统生物学的看法:控制某个生物行为的基因,不一定在这个生物的体内,它可能存在于遥远的目标生物或寄生者体内。
四、 自私基因理论矛盾的终极解决:“复制因子”与“载体”
在全书的最后,道金斯运用上述逻辑,完美厘清了“基因”与“生命个体”在达尔文进化论中的不同生态位,解决了一直以来的矛盾:
1. 概念的明确区分
- 复制因子(Replicator):
自然选择的基础单位。它们不直接参与外部世界的劳作,只负责自我复制,并将自身拷贝世代相传(如 DNA、基因、Meme)。- 载体(Vehicle):
复制因子为了生存和繁衍,在物理世界中构建出的临时保护罩/生存机器。它们不复制自身,只负责在世界上观察、捕食、御敌(如我们的身体、动物个体、乃至蜂群)。2. 个体选择 vs 基因选择 / 类群选择
- 道金斯指出,科学界以往关于“个体选择”和“基因选择”的争论是一个分类学误区。
- 基因和个体根本不是竞争对手,它们分饰着**“复制因子”和“载体”**这两个互补的角色。
- 真正的竞争发生在**“载体”的层次**上(例如“个体选择”与“类群选择”的竞争)。
3. 为什么生命“个体”是一个完美的、高度结合的载体?
- 减数分裂的公平性(共享唯一的未来通道):
你身体里的所有细胞(除了性细胞)都拥有相同的基因。而所有这些基因要抵达未来的唯一渠道,就是通过减数分裂产生的精子或卵子。
因为它们共享一条出路,在同一个未来事件中得到相同的回报,所以它们在演化上达成了完美的妥协与合作。这使得我们的身体成为了一个高度一致、功能极致、有共同目标的“单一个体载体”。- 为什么“狼群/群体”无法成为一个融合的载体?
因为狼群中的每只狼基因不同,它们并不共享同一个繁衍出口。一只狼可以通过牺牲同伴来最大化自己的利益。因此,狼群只是一个松散的集体,狼个体才是真正的载体。- 超级载体(Superorganism)的特例:蜂群
蜂群里的所有工蜂几乎不繁殖,整个蜂群的未来完全寄托在“蜂后唯一的卵巢”上。因为它们也变相共享了同一个未来的通道,所以蜂群在行为上表现得像一个高度有机的结合体——一个单一的“超级载体”。总结
达尔文主义的生命大戏中,基因是唯一不朽的主角(复制因子),而生命体则是它们为了共同抵达未来、通过减数分裂这一“公平通道”而联合构建的精致舞台(载体)。
当我们把表型延伸到整个世界,我们会发现,基因可以利用它所触及的一切机会(无论是筑坝、制药、操纵宿主还是凝聚身体)来确保自身的生存。生命个体那一层复杂而精密的外壳,只是自私的基因在演化中为了最大化自身利益所留下的、最宏大也最精美的延伸表型。
有没有能操纵人的蛊术, 想试试感觉.
巫蛊.
在这段终章的压轴论述中,理查德·道金斯回答了演化生物学中最深奥的一个问题:既然生命在根本上是自私复制因子的战场,为什么这些因子不选择在原始汤中自由漂浮,而是选择聚集成细胞、多细胞生物,并遵循单细胞“瓶颈”式的生命循环?
道金斯将这一宏大问题拆解为三个渐进的演化阶梯,并对全书的“自私基因”与“延伸表型”世界观做出了终极总结:
Note
一、 生命演化的三大阶梯
阶梯 1:为什么基因要组成细胞?(生化生产线与细胞膜)
- 现象与原因:
单个基因只能制造一种蛋白酶,而细胞内复杂的生化合成(如人体的“制药工厂”)需要流水线式的接力反应。多种基因必须相互合作,用不同的酶催化连续的步骤,才能合成最终产物。- 演化机制:
自然选择不倾向于选择孤立的基因,而是像选择“一船桨手”一样,偏爱那些能够彼此协作、在同一条化学路线上完美配合的基因群。- 细胞膜的诞生:
为了防止这些好不容易聚在一起、能高效合作的化学物质流失或渗漏,演化出了细胞膜,充当它们的“试管架”和保护介质。阶梯 2:为什么细胞要组成多细胞生物?(体型与特化分工)
- 原因 1(体型优势):
大并不一定是绝对的好,但体形变大让生物在捕食、防御天敌、以及探索全新生态位时拥有不可替代的物理优势。- 原因 2(分工与专长):
多细胞聚合允许细胞进行极端特化(分工)。一些细胞专门负责感知,一些负责传递电信号(神经),一些负责运动(肌肉),一些专门负责繁殖(生殖细胞)。所有细胞各司其职,其整体运作效率远高于单打独斗。因为这些细胞都是同一个受精卵克隆而来的(基因完全相同),所以普通体细胞可以心安理得地为少数生殖细胞服务,共同让基因流传下去。阶梯 3:为什么多细胞生物要经历单细胞“瓶颈(Bottleneck)”的生命循环?
无论是体形多庞大的大象,其生命都必须“挤过”受精卵这一个单细胞的窄口(瓶颈),然后发育变宽,最终的目标又是为了制造精子或卵子这一个单细胞。道金斯通过对比“单细胞孢子繁殖(瓶藻)”与“身体碎片断裂繁殖(散藻)”,提出了瓶颈生命循环的三大决定性支撑理由:
- “回到绘图板”(Return to the drawing board):
复杂器官的重大进化不可能通过在祖先原有器官上“敲敲打打”来实现(你无法把螺旋桨发动机改装成喷气式发动机)。生命在每一代都经历单细胞的“瓶颈”,意味着它抛弃了父母已经成型的、带有历史包袱的实体器官,回到了最初的设计起点。它只遗传父母的设计程序,然后从零开始,在每一代重新构建一个可能带有微调和改良的、更完美的新器官。- “准时的时间循环(日历机制)”:
因为每一代生命都必须从受精卵出发、经历几乎相同的生长旅程,这为胚胎发育提供了一个标准化的、规律重复的时间表。特定的基因在特定的时间点被精准地打开或关闭(如同一本严格遵守的日历)。没有这种精确的时间规划,像鹰眼、燕子翅膀这样精密复杂的器官是绝无可能发育出来的。- “细胞的基因统一(消除内耗)”:
- 在不经历瓶颈的“断裂繁殖(散藻)”中,子代的细胞来自母体不同的部位,这些细胞有不同的突变历史,基因并不完全一致。细胞之间会为了自身的增殖而互相竞争、内耗,导致个体不再是一个紧密合作的整体。
- 但在“单细胞瓶颈(瓶藻)”中,子代的所有细胞都克隆自同一个孢子,具有 100% 完美的基因一致性。它们在演化上没有任何利益分歧,可以全心全意地快乐合作。自然选择的筛子也因此得以整株植物(或整个生物体个体)为单位进行选择,而不是以单个细胞为单位。
二、 终极总结:自私基因与延伸表型的生命全景图
在全书的尾声,道金斯引导我们跳出生物个体的框框,将思维彻底逆转:
- 复制因子(Replicator)与载体(Vehicle)的各司其职:
- 基因(DNA)是唯一的复制因子,它们是演化的最初动力和基础单位,负责在世代交替中不朽地自我复制。它们不直接作用于世界。
- 身体是个体载体,它们是基因合作构建的、用以与环境打交道的临时工具。它们不复制自身,只负责保护并传递复制因子。
- 以往科学界关于“个体选择”和“基因选择”的争论只是概念混淆。基因是复制因子,身体是载体,它们分饰两角、互相补充。
- 身体只是临时聚合的产物:
为什么我们最熟悉的载体是“身体个体”而不是“生物群体(如狼群)”?因为身体内的所有基因共享着唯一的未来通道(减数分裂产生的精卵),而狼群中的个体并不共享同一个出口。- 无国界的延伸表型之网:
直到今天,基因的表型作用也从未被物理身体的皮肤界限所限制。自私的基因端坐于因果之网的中心,它的影响力箭头向外辐射,跨越空间,操纵着无生命的物体(如海狸的湖)、其他生物的身体与神经系统(如寄生虫、病毒和布谷鸟)。- 不朽的复制因子是生命的唯一本质:
我们习以为常的“庞大、复杂、目的明确的生命体”,只是自私基因在演化中为了共同抵达未来,通过“单细胞瓶颈通道”妥协、凝聚而成的阶段性产物。无论在宇宙的哪一个角落,生命出现、繁衍、并进化出惊人复杂性的唯一源头和本质需求,只有那不朽的、自私的复制因子。
延伸表型
“延伸表型”的中心法则:动物行为倾向于最大化指导此行为的基因的生存,无论这些基因是否在做出此行为的动物体内。
第14章 基因决定论与基因选择论
这章怎么开始讲哲学了.
曾有一位书评人针对威尔逊1978年出版的《论人的天性》(On Human Nature)评论道:“虽然他并未像理查德·道金斯在《自私的基因》里那般激进,将与性有联系的基因都认为是‘薄情’的,但是威尔逊还是认为人类男性有着遗传而来的一种天性,倾向于实行一夫多妻制,而女性倾向于忠贞的两性关系。他的潜台词无非是:女士们,别责怪你的丈夫出去乱搞了,他们在遗传上就是如此编程设置的,那可不是他们的错。基因决定论一直就徘徊在后门外,想要偷偷潜入进来。”(Rose 1978)。这位书评人的暗示很明确:他批评该书的作者相信存在一些会迫使男人们不可救药地成为玩弄女性的人的基因,别人却还不能因此指责他们婚内出轨。看到这篇书评,读者就会产生这样的印象:那些书的作者在“天性与教化”的争论中支持前者,甚至是彻头彻尾的遗传论者,有着男性沙文主义的倾向。
实际上,我的书中关于“薄情的雄性”那一段,原本并非是关于人类的。那只不过是一个数学模型,对象不是任何一种确定的动物(我写的时候心里想的是某种鸟,不过也无所谓啦)。很明确的一点是,那不是关于基因的数学模型(下文会谈到这一点),要真是关于基因的模型,那它们就不是与性有联系的了,而是受到性的限制。在梅纳德·史密斯(Maynard Smith 1974)看来,那是关于“策略”的数学模型。之所以设定“薄情”的策略,不是因为这是雄性们的行为方式之一,而是因为它是两种假设出来的可选策略之一——与之相对的是“忠诚”的策略。这个非常简略的模型是为了描绘某些特定条件而存在的:处在一些条件之下,薄情的策略会为自然选择所青睐;而处在另一些条件之下,得到青睐的则是忠诚的策略。在这样的研究中,并没有预先假定雄性会更有可能拈花惹草,而非忠诚。事实上,在我发表的一项模拟运行中,最精彩的就是一个混合型的雄性群体,其中采取忠诚策略的比例还略微占优一些(Dawkins 1976a,p.165,还可以参见Schuster&Sigmund 1981)。罗斯评论中的误解还不止这一处,而是多处混合式的误解,体现了一种毫无节制地急于去误解的冲动。这与覆雪的俄军军靴,或是正渐渐取代男人的角色、夺走拖拉机驾驶员工作的小小黑色芯片本质上是一回事,它们都是某类有着强大影响力的迷思的表现形式。具体到我们要谈的问题上,那就是关于基因的巨大迷思。
争强好胜的小孩子.
沙文主义
资产阶级侵略性的民族主义,沙文主义的基本特征是,把本民族利益看成高于其他一切民族的利益,鼓吹本民族是世界上最优秀的民族,煽动民族仇恨,主张采用暴力手段征服、奴役其他民族。男性沙文主义:是一种认为男性必定优于女性的理念。
“是什么” 是推不出 “如何做” 的.
事实就在那里, 价值却是主体赋予的.
当我们说一样事物决定另一样事物时,到底意味着什么?哲学家更多考虑的是因果关系,可能还会给出证明。但是对于专业的生物学家而言,因果关系只不过是简单的统计学概念而已。从实践上来讲,我们永远不可能证明一个特定的观察到的事件C导致了一个特定的结果R,尽管我们常常会认为这是极有可能发生的。生物学家在工作中往往会从统计角度来证明:R类事件总接着C类事件发生。要得出这样的结论,他们需要这两类事件的若干对实例才行,一则传闻可远远不够。
即便是观察到事件R很可靠地趋向于发生在事件C之后,并总是间隔一个相对固定的时间,那也只能得出一个可能会成立的假说,认为事件C会导致事件R。在统计学方法的限制之下,只有当事件C由实验者来实现,而非仅仅由观察者记录到,并且仍能可靠地导致随之而来的事件R发生时,这个假说才算是被证实了。并非每个事件C都必须跟着一个事件R,也并非每个事件R都必须接在一个事件C之后。(谁还没面对过这样的争辩——“吸烟不可能导致肺癌,因为我就认识一个不吸烟的人死于肺癌,还认识一个烟瘾很大的人活到九十多岁,身体还很硬朗。”)统计学方法本就是用以帮助我们去评估,在任意确定的概然性置信度水平上,我们所得到的结果是否确实意味着一种因果关系的方法。
那么,如果拥有一条Y染色体真的能够造成一些因果性的影响,比如音乐能力或者对编织的喜爱,这将意味着什么?那就意味着,在某些确定的人群内,在某些特定的环境下,一个观察者如果掌握了某个人的性别信息,那么相对于不掌握这些信息的观察者,前者就将能够对这个人的音乐能力做出统计学上更为准确的预测。重点在于“统计学上”。另外,为了更便于评价,让我们再加入“其他一些让两者相同的条件”。观察者可能会得到一些附加的信息,比如说这个人的受教育程度,或是家庭教养情况。这些信息可能会让观察者调整甚至反转自己先前基于性别做出的预测。如果女性在统计学意义上比男性更享受编织的乐趣,这并不意味着所有女性都享受编织的乐趣,甚至都不意味着女性中的大多数会享受这种乐趣。
…
人们在接受以下观点时似乎没什么困难:“环境”在一个人的成长过程中所发挥的影响作用是可以被改变的。如果一个孩子有过一个糟糕的数学老师,那么人们可以接受这样的场景:由这位糟糕老师所引发的数学知识匮乏可以通过接下来一年好老师的教学加以弥补。可要是说这孩子的数学问题可能有着基因上的根源,那就会让听者的想法向着“没希望了”那个方向发展:如果是基因的原因,“那就是写在基因里的”,是“确定性的”,无论做什么也挽救不了了。你可能还会放弃继续教授这个孩子数学的打算。这根本就是有毒的垃圾思想,恶劣程度几乎与占星术差不多。理论上来讲,基因的原因和环境的原因是彼此没有差别的,两者造成的某些影响都是很难逆转的,而另一些影响很容易逆转。有些影响可能通常是难以逆转的,但只要用对了方法就会变得很容易。重点在于,没有什么一般性的原因令我们可以去期望:基因的影响会比环境的影响更难以逆转。
这章讨论了很多关于自由意志和决定论的东西.
我觉得讨论这个问题可能需要看一看量子力学.
以上讨论对于解决另一个时下非常流行的争论也会有侧面的帮助,能让人们以正确的方式来看待这个问题。这个问题目前的争议很大,甚至有点情绪化,那就是人类的各种精神能力的背后是否有着显著的基因变化作为基础。我们之中的某些人是否从基因上就比别人更有脑子呢?我们用“有脑子”这个说法想要表达的意义也有着很大的争议,并且的确应该有这样的争议。不过我主张,无论这个说法在此处取什么样的含义,以下的论点是不能被否认的:(1)曾经的某个时间点上,我们的祖先不如我们有脑子;(2)在所有我们祖先的谱系中,一定有过“有脑子程度”方面的增长;(3)这种增长是通过进化来实现的,可能还是由自然选择推动的;(4)无论是否是自然选择推动的,至少表型方面的部分进化改变反映了深层次的基因改变——发生了等位基因的替换,结果代际的精神能力平均水平提高了;(5)因此根据定义,人类群体一定曾经在“有脑子程度”方面有过显著的基因变化,至少在远古时期是这样的。当时,有的人与同时代的人相比,基因上来讲更聪明一些,另一些人从基因上来讲则相对要傻一些。
第15章 对于完美化的制约
适应论
一、 什么是“适应论”及其学术争论
- 批判者的定义:
理查德·莱文廷(Richard Lewontin)与史蒂芬·古尔德(Stephen Jay Gould)是适应论最著名的批判者 [1.1]。他们认为,适应论者在缺乏确凿证据的情况下,盲目假定生物的所有形态、生理和行为都是完美的、最优的演化方案 [1.1]。他们批评这种“凡事皆有其完美功能”的倾向是草率的 [1.1]。- 辩护者的观点(以凯恩 A.J. Cain 为代表):
凯恩等学者则坚决站在适应论一边 [1.1]。他指出,许多在过去被嘲笑为“无用”、“装饰品”或“纯粹历史遗迹”的生物特征,在经历深入研究后,都被证明具有至关重要的生存功能 [1.1]。
- 实例一: 丛林蜗牛壳上的条带,曾被认为毫无意义,但研究证明它在维持形态多样性上受到强烈的自然选择压力 [1.1]。
- 实例二: 节肢动物土线(Polyxenus)身上的“小饰品”,最终被证明是其生活的重心所在 [1.1]。
二、 适应论在科学研究中的积极作用(“利”)
道金斯指出,即使适应论在理论上存在争议,但它在客观上是一件极有价值的**“科学启示工具”**,它极大地激励了科学家去做出伟大的发现 [1.1]:
- 卡尔·冯·弗里希(Karl von Frisch)发现蜜蜂和鱼类的彩色视觉:
冯·弗里希之所以能通过实验证实这一点,是因为他本能地拒绝相信“花朵的艳丽颜色只是偶然、毫无成因的” [1.1]。这种坚信“花色必有功能”的适应论信念,驱动他完成了里程碑式的研究 [1.1]。- 提出更具检验性的生理假说:
在面对庞大、复杂的感官系统或运动系统时,适应论推理可以帮助科学家在无数种可能性中,筛选出最符合演化效率、最可能为真的假说,并优先予以实验验证 [1.1]。三、 适应论的盲区与局限(“弊”)
然而,道金斯也以极度坦诚的态度承认,对适应论的盲目笃信可能会让科学家变得自满和盲目,从而忽视合理的科学质疑 [1.1]:
- 蜜蜂舞蹈语言的公案:
温纳(Wenner)曾对冯·弗里希的“蜜蜂舞蹈传达方向与距离信息”假说提出质疑 [1.1]。温纳并不否认舞蹈含有信息,但他怀疑其他蜜蜂是否真的能看懂并利用这些信息 [1.1]。- 道金斯的自我反思:
道金斯承认,由于自己深受适应论影响,当时本能地觉得“温纳肯定是错的”,因为“蜜蜂耗费巨大精力跳出这么复杂的舞却毫无用处,这让适应论者寝食难安” [1.1]。正是因为这种自满,他自己绝对不会去设计实验验证温纳的质疑 [1.1]。- 不迷信带来的科学进步:
正因为温纳提出了不那么“适应论”的怀疑,才激发了J.L.古尔德(J.L. Gould)设计出极为精妙的实验,最终完美地确证了冯·弗里希理论的正确性 [1.1]。
总结
道金斯在这段话中传达的意思是:
- “适应论”作为一种绝对教条(坚信大自然一切皆完美优化)在理论上是有局限的。 [1.1]
- 但作为一种“工作假说”或研究直觉,它是极其有力量的。 它能指导我们不轻易放弃对“无用器官/奇特行为”的探究,从而挖出背后隐藏的生理学和演化真相 [1.1]。
- 最理想的科学态度是:保持适应论带来的探索热情,但永远不让它阻碍我们对客观事实的审视与质疑。 [1.1]
六种制约因素
在这段选自理查德·道金斯(Richard Dawkins)著作的文本中,作者系统地论述了限制自然选择使生物达到“完美设计”的六种制约因素(Constraints on Perfection)。以下是这六种制约因素的详细总结、解释以及文中给出的对应示例:
1. 时间滞后 (Time Lags)
- 解释:
生物的表现型往往落后于当前的环境。影响其生理或行为建立的基因,是在较早的时期为了应对与今天不同的环境条件而被自然选择出来的。进化需要一定的时间跨度,在环境发生快速或剧烈改变时,生物往往来不及进化出完美的适应性。- 示例与论证:
- 塘鹅(Gannets)的产卵数: 塘鹅通常只下一个蛋,但实验表明它们完全有能力成功孵化并养育两个。学者拉克提出,这可能是由于过去的食物匮乏导致了一只的最优进化,而至今它们还没有足够的时间进化到适应新改善的环境。
- 刺猬的防御行为: 刺猬应对捕食者的本能是蜷成刺球。但在面对人类发明的机动车时,这种古老的防御行为不仅无效,反而往往致命。
- 人类的现代行为(避孕、收养、阅读、数学等): 这些行为在现代环境下可能不具备传统意义上的适应性,因为人类现代生活环境的改变速度极快,远超进化能够跟上的标准。这些行为是基因在适应更新世祖先环境后,在面对极端改变的现代人造世界时产生的副产品。
- 飞蛾扑火: 在人造光源发明前,飞蛾依靠无穷远处的光源(如天体发出的平行光)保持固定夹角来导航。然而当面对近处散发非平行光的烛火时,这种原本极具生存价值的习性会导致飞蛾飞出向内螺旋的轨迹,从而导致自焚。
2. 历史性制约 (Historical Constraints)
- 解释:
自然选择没有远见,它无法像工程师一样从一张白纸开始重新设计,而必须在已有结构的基础上一件一件、修修补补地进行改造(即“修补匠”而非“设计师”)。在这个过程中,不仅最终产物要能存活,每一个中间过渡状态也必须能够存活且表现更优。局部最优(适应性景观中的“小山包”)往往会阻碍生物向全局最优迈进。- 示例与论证:
- 螺旋桨到喷气发动机的类比: 如果限制工程师只能在保持飞机飞行能力的前提下,每次只更换一个零件来把螺旋桨发动机改装成喷气发动机,其最终成品必然怪异且可能无法起飞。
- 喉返神经(Recurrent laryngeal nerve): 在哺乳动物(尤其是长颈鹿)中,该神经从脑部到喉部的距离极短,但它却绕过了胸部的主动脉后侧。在鱼类祖先中这原本是直接路径,但随着脖子变长,由于在胚胎期重新设计发育路径的成本过高,自然选择只能不断让该神经拉长,形成了极其低效的历史遗留路径。
- 比目鱼与脊椎动物视网膜: 比目鱼两眼长在同一侧的扭曲面孔,以及脊椎动物眼睛中“装反了”的视网膜(视细胞朝后,光线必须穿过电路网络),都是进化只能在原有方案上修补而无法推倒重来的证明。
- 美洲热带蝴蝶的米勒拟态: 六种截然不同的警示图案在雨林中共存,因为图案之间差异过大,单点突变无法跨越两者的鸿沟,导致它们永远被局限在各自的局部最优状态里。
- 犀牛角: 印度犀牛有一只角,非洲犀牛有两只。这并非因为一角或两角分别最适应其大陆,而是由于起始发育系统微小的不同,使它们在通过种内竞争(威吓)做出响应时走向了不同的局部平衡。
3. 可用的基因变化 (Available Genetic Variation)
- 解释:
自然选择的发生必须以存在相应的基因变化(突变)为前提。即使某种性状从常识或工程学上看非常有益,如果该突变从未在物种中产生,进化也无法凭空将其制造出来。此外,有些突变比其他突变在数量和概率上更容易发生,从而引导生物走向了特定的进化路径。- 示例与论证:
- 猪没有翅膀: 猪无法长出翅膀,很大程度上在于它们的谱系中缺乏这种基本的基因变化。
- 家畜性别比例的人工选择: 在乳品业中,若能培育出多产雌性、少产雄性牛犊的牛种会带来巨大经济收益,但所有相关的人工选择尝试均以失败告终,说明自然界中缺乏实现这种性别偏差的基因变化。
- 雄性哺乳动物不分泌乳汁: 虽然雄性携带雌性祖先传下的全部乳汁分泌基因,且理论上可以通过激素诱导分泌,但在自然状态下它们仍不分泌乳汁,这可能是因为在进化中缺乏使其自发敏感于调节激素的可用突变,或者该演变未能提供足够的收益。
- 鸟类(羽毛翅膀)与蝙蝠(翼膜翅膀): 哺乳动物祖先可能同时面临羽毛和翼膜的发展机会。但由于翼膜突变在数量上相对更易发生或出现更早,使蝙蝠在翼膜适应性的斜坡上走得太远,从而在竞争中关闭了进化出更优秀的羽毛翅膀的可能性。
4. 成本与材料的制约 (Constraints of Costs and Materials)
- 解释:
“天下没有免费的午餐”。每一种适应性都有其代价,资源是有限的。投在某一方面的物质、能量、时间或结构强度,必然意味着要从其他方面扣除(如:把资源花在翅膀飞行上,可能就会减少产卵量)。自然选择所能做到的并非工程师眼中的绝对完美,而是一种“改善化”(Melioration)——在相互冲突的各种经济和成本制约下达成的一系列折中与妥协。- 示例与论证:
- 大金掘土蜂与“协和式谬误”: 雌性掘土蜂在争夺洞穴的战斗中表现出类似人类“协和式谬误”的行为,即在一场战斗中坚持的时间与它们自己往洞里放入的蝈蝈数量(先期投资)成正比,而非与洞穴的实际价值挂钩。
- 感官与运营成本(对比平原爱沙蜂): 这种看似不完美的行为源于大金掘土蜂无法评估洞中食物的数量,这一感官系统的缺失可能也是一种成本选择。其亲缘物种平原爱沙蜂具备每天早上巡视评估巢穴存货的能力,但它们平时会关闭这一技能(只在早晨使用),说明这种评估技能本身要消耗高昂的时间或能量成本。大金掘土蜂由于繁育模式简单,进化出并维持这种复杂的感官及神经系统的“制造成本”大于收益,因此自然选择并未保留它。
5. 在一个层次上由于另一个层次的选择作用所造成的不完美 (Imperfections at one level due to selection at another level)
- 解释:
自然选择并非在一个单一的层面上起作用。新达尔文主义认为,选择的基础运作层面在“自私的基因”或较小的基因片段上,而非生物个体或群体。在基因层面上的被选择,往往会导致个体层面上显现出明显的低效或不完美。- 示例与论证:
- 一夫多妻制的低效: 在许多一夫多妻制动物中,少数强壮雄性占领雌性,大量单身雄性不繁殖却消耗着近一半的群体食物。从群体效率来看这极为浪费,但从基因自我复制和竞争的角度来看却是稳定且和谐的。
- 杂合体优势(如人类镰状细胞贫血): 携带一个镰状细胞贫血基因的杂合体对疟疾具有抵抗力(这在基因选择中是有益的),但这种机制通过孟德尔式的随机重组(抽奖),无可避免地会导致其后代中必定会产生一定比例的携带两个贫血基因的纯合体。纯合体个体会表现出严重的贫血缺陷,这就是基因层次选择导致个体层面不完美的经典例子。
6. 由环境的不可预测性或“恶意性”造成的错误 (Errors due to environmental unpredictability or “malevolence”)
- 解释:
任何生物对环境的适应都是基于统计学意义上的长期平均条件。面对每时每刻变化繁复的环境细节,生物不可能对每一次意外都做出精确预测,因此常常犯下不可避免的“错误”。此外,环境不仅是死的自然条件,还包括其他活的生物(如捕食者、寄生者),它们具备主动的“恶意性”,会针对受害者进行伪装和操控。- 示例与论证:
- 树栖动物掉落: 树栖动物的行为程序一般基于“不要走太细的树枝”等统计学上的有效规则,但具体的树枝硬度、落叶分布千差万别,导致它们偶尔会犯错掉落。
- 巨蟒的伪装: 猴子以为踩在一根粗壮的树枝上,结果却是一条伪装的巨蟒。
- 知更鸟喂养杜鹃: 知更鸟不顾自身利益,在巢中长期且重复地抚育寄生的杜鹃雏鸟。这不仅是统计意义上的偶然失误,而是由宿主与寄生者之间恶意操控的“协同进化军备竞赛”所导致的、一代代重复出现的行为扭曲。
尾注
特德·伯克(Ted Burk)在还是我的研究生的时候找到了进一步的证据证明蟋蟀里存在这类假的优势序位。他还发现一只雄性蟋蟀如果最近刚击败了另一个雄性时,它更有可能对一个雌性示爱。这应该被命名为“马尔博罗公爵效应”,因为马尔博罗公爵夫人的日记中有一篇如此记载着:“大人今天从战场上回来,等不及脱掉马靴就和我缠绵了两次。”《新科学家》杂志的下述报道也许能够提供另外一个名字,该报道描述了雄性激素睾酮水平的变化:“大赛前24小时网球选手的睾酮水平翻倍。赛后,胜利者的睾酮水平维持不变,失败者的则会降低。”
糟糕的事并不仅仅局限于与遗传上和你关系太近的人交配,太远距离的族外婚也同样不好,因为不同支之间会有遗传不亲和性。最佳的中间距离很难准确地预测。你应该和你的第一代堂兄妹结合吗?与第二代或第三代堂兄妹结合呢?帕特里克·贝特森(Patrick Bateson)尝试询问日本鹌鹑倾向于一个怎样的距离。在一个名为阿姆斯特丹装置的实验设备中,研究者让鹌鹑们在迷你橱窗后的一排异性中挑选一个。它们大都挑选了第一代堂兄妹,而非亲兄妹或其他不相干的鹌鹑。进一步的实验显示,年幼的鹌鹑会记住同一窝里同伴的特征,在之后的生活中,会倾向于找具有类似特征的作为性伴侣,但它们不会找过于相似的。
第一代堂兄妹吗, 有意思.
恰尔诺夫当时正在写一些关于社会性昆虫以及不育阶层的起源方面的东西,但他的论据的作用其实更广泛,所以我要将其运用到一般的情况上来。试想一个一夫一妻制种群里的一只即将成年的幼年雌性,并不一定要是昆虫。它现在会面临一个两难境地,究竟应该离开然后试着生育自己的后代呢,还是留在父母的巢穴里帮忙照看更年幼的弟弟妹妹?基于该物种的繁殖习惯,它能很确定自己母亲会长期继续生育它的亲弟弟和亲妹妹。根据汉密尔顿的逻辑,这些弟弟妹妹对它的遗传学价值和它自己的后代是一样的。既然考虑到了遗传学关系,那这只年轻的雌性就应该不再纠结于这两种选择了;它不关心究竟是走还是留。但是它的父母,则会很关心究竟它做出怎样的决定。从它年长的母亲的角度来看,这个选择决定了它是有更多儿女还是孙辈。新的儿女的价值从遗传学上来说比孙辈要高一倍。如果我们把子代究竟是走还是留下帮助父母看作一个亲代与子代的冲突的话,在这场冲突里亲代显然很容易最终获胜,因为只有它们视其为一个冲突。
这就像两个运动员之间的一场较量,其中一个运动员如果赢了就能够获得1 000英镑的奖励,而他的对手无论输赢都能得到1 000英镑。我们可以预测到前一个选手会更加努力,如果两人本来就实力相当的话,那他很可能会赢。其实恰尔诺夫的观点比这个比喻还要强得多,因为无论他们的收益如何,全力以赴地进行一次比赛对很多人来说并不是一个很高的代价。那样一个理想化的奥林匹克对于达尔文游戏来说实在太奢侈了,在达尔文游戏里,在一个方面做出的努力就意味着在另一个方面会有所欠缺。就像是你在一场比赛中投入过多精力的话,你就很难赢得下一场比赛了,因为那时你已精疲力竭。
随着物种变化,条件也会有所不同,因此我们很难每次都预测出达尔文游戏的结果。但是如果我们只考虑最亲的基因相关性,并且假设一个一夫一妻的配偶制度(这样女儿才能够确信它的弟弟妹妹们是亲弟弟妹妹),我们可以推测出年长的母亲会成功地让它刚成年的女儿留下来帮忙。母亲会得到一切,而女儿自己不会有任何动力去反对母亲,因为对它而言,手上的选择并没有什么区别。
现在来看,强调精子和卵子的大小区别就是性别的基础似乎有些误导作用。就算一个精子小而廉价,但要制造百万计的精子并成功地在所有的竞争条件下将它们注入雌性体内并不是一件轻松的事。我现在倾向于用如下方法来解释 雄性和雌性之间的基本不对称性。假设我们有两个性别,它们并不包含雄性或雌性的特征。我们用一种中性的方式将它们命名为A和B。唯一需要注明的是任何一次配对都必须发生在A和B之间才行。
现在,任何一只,无论A还是B,都面临这一个抉择:用于与对手战斗的时间和精力就没办法用来照顾后代了,反过来也一样。它们俩中任何一个都需要在这两个矛盾的选择中找到一个平衡。我接下来要讲到的观点就是,A们可能会与B们找到两个不同的平衡点,一旦达到,它们就很可能有了一个逐渐变大的区别。假设两种性别的动物,也就是A们和B们,从一开始就有了不同。一个通过在后代上投资而获得成功,另一个则是在战斗(我用“战斗”一词来指代所有同性间的竞争)中付出努力而得到成功。一开始两性之间的区别还十分微小,因此我的观点就是存在一种固有的趋势使这种区别变大。好比A一开始由战斗带来的繁殖优势就比亲子行为带来的优势大,而B恰恰相反,亲子行为在它们这儿能带来比战斗稍微高一点的繁殖优势。
举个例子来说,这就意味着尽管A当然也能从照顾后代中获益,但A中一个成功的照看者和一个不成功的照看者之间的区别,会小于A中一个成功的战士和不成功的战士之间的区别。在B群体中,则是完全相反的。因此,对于一定量的付出来说,A会通过努力战斗来提高自己的优势,而B更可能把注意力从战斗转向照看后代。
因此在接下来的世代中,A们就会比它们的父母们战斗得更多一些,而B会比它们父母们战斗得少些而多花一些时间照看后代。战斗能力最强的和最弱的A之间的区别将变得更大,而照看能力最强的和最弱的A之间的区别将变得更小。这样一来,通过在战斗方面付出努力,A可以得到更多收益,而照看后代的收益变得更小了。随着世代更替,相反的事情也发生在B的群体中。这里的关键点是两性间一个微小的初始差别能够自我强化:选择可以发源于一个初始的、微小的不同,然后将其慢慢地变大,再变大,直到A变成了现在我们所说的雄性,B则是我们所说的雌性。那个初始区别小到可以随机产生。当然,两性的初始条件也不大可能是一模一样的。
我们的意图是要在一个性别内找到一个进化稳定的混合策略,并与另外一个性别的进化稳定的混合策略相匹配。梅纳德·史密斯自己又进一步地发展了这个观点,而艾伦·格拉芬和理查德·西布利(Richard Sibly)也独立地做了差不多的事。格拉芬和西布利的论文在理论上要更高深一点,而梅纳德·史密斯的更方便用文字解释。简要地说,他开始考虑两个策略,坚守(Guard)和离弃(Desert),供两性任意选择。正如我“羞怯/放荡和忠诚/薄情”的模型一样,有趣的问题在于,雄性的哪种策略组合与雌性的哪种策略组合在一起是稳定的?答案取决于我们对该物种特定经济状况的假设。有趣的是,无论如何改变经济状况假设,我们都得不到一个整体连续的定量变化的稳定解。该模型倾向于落入四个稳定解之一。这四个解都依据符合条件的物种来命名。它们是鸭型(雄性离弃,雌性坚守)、棘鱼型(雌性离弃,雄性坚守)、果蝇型(双方离弃)以及长臂猿型(双方坚守)。
还有些更有趣的东西。还记得第5章里ESS模型可以在两种结果之间任选其一,且两者同样稳定吗?好吧,这对于梅纳德·史密斯模型来说也是正确的。其中最有趣的一点是,对比其他策略对,那个满足这种结果的策略对在同一个经济情况下保持着共同稳定。举例来说,在一组情况下,鸭型和棘鱼型都是稳定的。究竟两个中哪一个最终胜出取决于运气,或者说得更准确一点,取决于进化历史上的偶发事件——初始条件。在另外一组情况下,果蝇型和长臂猿型则是稳定的。同样,在任何一个物种中,都是由历史偶然性来决定究竟哪一型最终胜出。但是没有任何情况能使长臂猿型和鸭型共同稳定,也没有哪种情况能使鸭型和果蝇型共同稳定。对亲和与不亲和的ESS进行这种“稳定对”(表示两种策略的组合)的分析能为我们重建进化历史提供一些有意思的结论。例如,它使我们相信在进化历史中,配偶系统中某些特定转换是可能的,其他的则不可能。梅纳德·史密斯通过简要枚举动物界的配偶方式来探索这些历史上的关系,其结论是这样一个令人难忘的反问:“为什么不是雄性哺乳动物负责哺乳呢?”
47第176页:但实际上,像那种情况一样,不存在任何摇摆现象,这是能够加以证明的。整个体系能够归到一种稳定状态上。我很抱歉这个论点是错误的。然而,这个错误很有意思.


雌性对雄性的诊断
当雄性被像医生一样的雌性仔细检查时,它们会如何反应呢?那些假装健康的基因会取得优势吗?可能一开始是的,但选择会导致雌性加强它们的诊断技巧,从健康个体中排除那些冒牌货。到最后,汉密尔顿相信雌性的诊断技巧会变得足够敏锐,以至于雄性不得不开始为它们的诚实做广告(如果它们真的做广告的话)。如果任何一个性广告在雄性中变得过于夸张的话,这一定是由于其本身就是一个健康的真实指标。雄性会进化得让雌性更容易看出它们是健康的——如果它们真的是的话。真正健康的雄性会很高兴宣扬该事实。不健康的个体当然不愿意,但它们又能做什么呢?如果它们不尝试去展示健康证书,雌性们肯定会对其得出最坏的诊断结论。顺带说一句,这里提到医生并不意味着雌性会对治愈雄性感兴趣,它们只对诊断感兴趣,并且这也不是一个利他主义的兴趣。我也假设我不需要为诸如“诚实”和“得出结论”这样的比喻道歉。
回到广告这一点上,这就有点像雄性被雌性逼着进化出了一个永远插在它们嘴里、能够让雌性清晰读数的医用温度计。这些“温度计”会是怎样的呢?好吧,想想雄性极乐鸟那不可思议的长尾巴。汉密尔顿的解释总体上来说更实在一些。鸟类的一个常见症状是腹泻。如果你有一根长尾巴,腹泻就很有可能弄脏它。如果你想要掩盖你被腹泻困扰这一事实的话,最好的办法就是避免拥有长尾巴。同理,当你想要广而告之你不存在腹泻这一事实的时候,最好的办法就是长出一个非常长的尾巴。那样的话,你尾巴很干净这一事实就变得更加引人注目。如果你根本就没什么尾巴,雌性们看不出它究竟干净与否,就只能得出最坏的结论。汉密尔顿可能不愿意自己来做出这个特定的关于鸟类寄生虫尾巴的解释,但这是他喜欢的解释方式之一。
为什么人类雄性的阴茎骨退化掉了? 可能是因为雌性选择!
我将雌性比作诊断医生,而雄性通过到处安放“温度计”来简化前者的工作。想一下医生用的其他一些诊断工具,例如血压计和听诊器,这样我产生了两三个对人类性选择的猜测。尽管我承认我发现它们的可靠性比不上趣味性,但我仍然会简要地讲一下。第一,一个关于为什么人类失去了阴茎骨的理论。人类阴茎勃起后会变得十分坚硬,以至于人们常常玩笑般地质疑里面竟然没有骨头。而事实上不少哺乳动物的阴茎里确实有着硬质的骨头,即阴茎骨,来辅助勃起。另外,这在我们的灵长类近亲中也很常见,就连我们最近的堂兄黑猩猩都有一块。尽管那是非常小的一块,而且它似乎也正朝着消失的主向进化着。似乎有这样一个趋势,即在灵长类中阴茎骨倾向于消失。我们人类,以及几种猴子,都已经完全失去了阴茎骨。所以,我们实际上失去了一个能让我们祖先很容易保持阴茎坚硬的骨头。相反,我们完全依靠一个水泵系统。尽管不大应该,但这感觉上的确是一个费力的、拐弯抹角的办法。而且,不幸的是,勃起可能失败,这直接影响了一个在野外生存的雄性的遗传成功率。最简单的一个补救方法是什么?当然非阴茎骨莫属了。因此,为什么我们不能进化出一个呢?曾经秉持“基因限制”论的生物学家不能再以“噢,需要的变种根本无法出现”这样的理由逃避问题。我们的祖先一直都有那样一块骨头,直到最近我们自己丢掉了它!为什么?
勃起在人类中完全是依靠血压。很不幸我们没有理由去相信勃起的硬度就像是医生的血压计,供雌性判断雄性的健康。但我们不只是吊在血压计这一棵树上。无论任何原因,只要勃起障碍成为某种疾病的先兆,无论是身体上还是精神上,这都可以成为使理论成立的一个版本。雌性所需要的只是一个可信赖的诊断工具。医生们不会在常规体检中做勃起测试——他们更喜欢让你伸出你的舌头。但已知勃起障碍是糖尿病及某些神经性疾病的先兆,更常见的原因是一系列心理因素——沮丧、紧张、压力大、过度疲劳、缺乏自信心等。(在自然界中,你可以试想低等级的雄性会有这种困扰。一些猴子用直立的阴茎作为一种威胁信号。)这并不是毫无道理,自然选择不断改善雌性的诊断技巧,雌性可以找出各种体现在语调上或埋藏在阴茎里的关于雄性健康的线索,以及他们处理压力的能力。但是一块骨头就能毁掉这一切!任何一个人都可以在阴茎里长出一块骨头,不需要他特别地强壮或健康。因此是雌性带来的选择压力迫使雄性失去了他们的阴茎骨,因为这样一来,就只有真正健康或强壮的雄性才能够做到真正坚硬的勃起,雌性也就能不受阻碍地做出诊断。
好清奇的角度. 类似的还有身高外貌.
为什么雌性有阴道瓣 (处女膜)?
按上面书里这个逻辑讲阴道瓣的留存可能是因为雄性选择.
阴道瓣相当于雌性身上的温度计, 它的破裂程度与先前是否有过性交经历存在某些相关性, 因此在选择过程中成为了雄性的诊断工具.
完整或破裂程度低的阴道瓣意味着雌性先前未曾有过性交经历, 雄性有把握确定自己与后代的血缘关系, 从而加强雄性投资. 而对于破裂程度高或是没有阴道瓣的雌性个体而言, 雄性会有更高的亲代不确定性.
因此雄性带来的选择压力迫使雌性保留了阴道瓣这一看似无用的结构.

都是疑罪从有.
雌性选择与雄性广告理论的结论
所以,现在的最大问题是:格拉芬的ESS模型所构建的这种世界,是扎哈维会认同的不利及诚实的社会吗?答案是肯定的。格拉芬发现确实有个进化稳定的世界同时满足扎哈维世界的几个条件:
1.尽管可以随意选择广告策略,雄性会选择正确反映它们真实品质的方案,无论这个方案是否会暴露它们很低的品质。换句话说,在ESS模型中雄性是诚实的。
2.尽管可以随意选择应对雄性广告的策略,雌性最终会选择“相信雄性”。在ESS模型中,雌性对雄性有着理所应当的“信任”。
3.广告是有代价的。也就是说,如果我们可以忽略品质和吸引力的影响,一个不做广告的雄性更容易成功(通过节省能量或者变得对捕食者不那么显眼)。广告是代价高昂的,正是由于它们有代价,所以雄性才选取了这样一个广告系统。之所以选择一个广告系统,是因为它实际上能够降低发布广告者的成功概率——在所有其他情况一样的前提下。
4.广告的代价于越差的雄性而言越高昂。同样程度的广告带给一个孱弱雄性的风险远高于其带给一个强壮雄性的风险。低品质的雄性相对高品质的雄性来说承受着由昂贵广告带来的更大风险。
NOTE
这段话深入探讨了演化生物学中极其著名的**“不利条件原理”(The Handicap Principle,在学术界也常被译为“累赘原理”或“障碍原理”**),并介绍了数学演化生物学家艾伦·格拉芬(Alan Grafen)如何用严谨的数学模型拯救了这一曾被主流学界边缘化的理论。
以下为您详细拆解这段话的含义,以及什么是“不利条件原理”:
一、 什么是“不利条件原理”?
“不利条件原理”最初由以色列生物学家阿莫茨·扎哈维(Amos Zahavi)于 1975 年提出。它用来解释一个生命科学中的核心谜题:动物在求偶或沟通时,为什么会发展出看似非常累赘、对生存毫无益处的特征?
- 经典案例: 雄孔雀华丽且沉重的尾羽。这羽毛不仅极耗能量,还会降低逃跑速度,增加被捕食的风险。从常规的“适者生存”来看,这简直是个生存灾难。
- 扎哈维的解释: 恰恰是因为这个特征是个**“不利条件”(即累赘),它才能成为一个“诚实信号”**。
- 如果一个雄性孔雀拖着这么沉重、危险的尾巴,依然能健康、强壮地活下来,就证明它的其他基因(如免疫力、力量、速度)绝对是极高品质的。
- 低质量的雄性根本“假装”不了——因为如果一个体弱多病的孔雀也想长出这么大、这么沉的尾羽,它很快就会累死或被天敌吃掉。
- 因此,代价高昂(不利)正是信号诚实性的保证。雌性之所以喜欢累赘,是因为累赘是一场极其严格且无法作弊的“生存考验”。
二、 这段话的核心大意是什么?
道金斯写下这段话,是为了**“认错并致敬”**。
在《自私的基因》第一版中,包括道金斯在内的许多主流演化生物学家都对扎哈维的理论嗤之以鼻,认为这在逻辑上说不通(一个降低生存率的特征怎么可能在进化中稳定遗传?)。
但后来,年轻的数学家艾伦·格拉芬做出了突破性的工作。他运用游戏规则(博弈论中的 ESS,进化稳定策略)建立了一套严密的数学公式,证明了扎哈维的直觉在数学上完全成立。道金斯被格拉芬的数学论证说服了,于是特意在后来的版本中加上这段话,向读者解释格拉芬是如何证明“诚实的累赘信号”能够在进化中达到稳定的。
三、 详解:格拉芬提出的四种“不利条件”类型
为了将含糊的语言转化为精准的数学模型,格拉芬将动物界中的“不利条件”细分为了四种方式:
- 合格型不利条件 (Qualifying handicap):
- 逻辑: 任何个体只要顶着这个累赘还能活下来,就自动获得了“合格证”。
- 比喻: “我背着 100 斤的沙袋依然跑完了马拉松,这证明我的体能绝对合格。”
- 展示型不利条件 (Revealing handicap):
- 逻辑: 雄性通过一些极耗精力或困难的举动,主动把本来隐藏的能力暴露出来供雌性检查。
- 比喻: 唱歌、跳极其复杂的求偶舞蹈,任何身体的一点虚弱都会在这种高强度展示中暴露无遗。
- 限制型不利条件 (Conditional handicap):
- 逻辑: 只有身体素质本身达到了极高水平的个体,身体才有能力发育出这个累赘。
- 比喻: 雄鹿的角,只有在营养极其充沛、身体极度健康时才会长得硕大,生病的鹿根本发育不出来。
- 策略选择型不利条件 (Strategic choice handicap):
- 逻辑: 个体“了解”自己的身体状况,并根据这个私人信息,自主决定要长出多大的累赘,以此作为博弈的策略。这是格拉芬模型的核心。
- 比喻: 身体极强的个体选择长出最大的累赘(因为对它而言代价较小);而身体稍弱的个体选择长出中等的累赘,因为如果逞能长出最大的,它自己会先吃不消。
四、 格拉芬模型的四项假设与最终结论
格拉芬通过以下四个极简且合理的初始假设,让计算机和数学公式去模拟进化的方向:
- 雄性品质有高下之分: 雄性有强壮、有弱小,雌性选强壮的在遗传上有利。
- 雌性不能直接看穿品质: 雌性无法肉眼透视雄性的基因,必须看他们的“广告”(比如尾巴长度、叫声)。
- 雄性“知道”自己的品质并决定广告强度: 雄性体内有生化传感器,能根据自己是否强壮,来调节自己长多长的尾巴或发出多大的叫声。
- 雌性可以自由决定相信谁: 雌性可以演化出任何策略,比如“无条件相信大广告”、“不信广告”或者“反着信”。
模型的最终结论:
在这种极度自由、甚至允许雄性随意撒谎的初始设定下,格拉芬模型在运行到进化稳定状态(ESS)时,居然自发收敛出了一个结果:
- 广告必须是有代价的(不利条件系统): 如果广告是免费的,弱小的雄性就会作弊,最终导致广告失去信用,系统瓦解。
- 诚实成了唯一的稳定策略: 只有当“广告的代价”对于强壮者来说容易承受、而对于弱小者来说难以承受时,游戏才能稳定。强壮者会长出最大的累赘,弱小者只能长出小的。
- 雌性也顺理成章地演化出“只相信大广告(大累赘)”的择偶策略。
格拉芬用这套优雅的博弈论模型,彻底说服了曾经持怀疑态度的演化生物学家,向世人证明了:在自然界中,有些时候,只有通过承受危险、高昂且看似无用的“累赘”,生命才能向配偶或对手证明自己真正的优秀。
如果格拉芬是对的——我认为他是——这对整个动物信号研究都相当重要。这甚至可能导致我们对行为的进化形势的看法来一个大转弯,也可能导致我们对本书中讨论的很多观点的看法发生大的变化。性广告只是广告的一个类型。如果扎哈维——格拉芬理论正确的话,将会完全颠覆生物学家对同性对手间的、亲代与子代间、不同物种的敌人间的关系的看法。我发现这个前景很令人担忧,这意味着我们再也不能以常识为由而排除那些几乎疯狂到极点的理论了。如果我们观察到某个动物正在做一些很傻的事,比如遇到狮子后开始用头倒立而不是远远跑开,它有可能只是在对雌性炫耀。它甚至有可能是在对狮子炫耀:“我是一个拥有如此高品质的动物,试图抓住我只会浪费你自己的时间。”(见197页)
但是,无论我认为一件事多么疯狂,自然选择总会带来一些其他的看法。当危机导致的广告效应上的增长超过危机带来的生命威胁时,一个动物甚至有可能在一群流着口水的捕食者面前表演后空翻。正是由于该姿势拥有危险性,它才更有值得炫耀的价值。当然,自然选择不可能倾向于无限的危险。当那种展示变成纯粹的有勇无谋的时候,它就会受到惩罚。一个危险或代价高昂的表演在我们看来也许很疯狂,但这真的与我们毫无关系,自然选择是唯一的审判官。
俗称装逼.
“在巢内帮忙”
在这一点上,以汉密尔顿的角度看来,最令人惊讶的是没有在更多的物种中出现照顾它们弟弟妹妹的不育工人。正如我们逐渐认识到的那样,更加广泛存在的是一种不育工人现象的稀释版本,被称为“在巢内帮忙”。在很多种鸟类和哺乳动物中,年轻个体会在离开种群组建自己的家庭之前,留在父母身边待上一两个季节,同时帮忙照看它们的弟弟妹妹。同样的基因也存在于弟弟妹妹的体内。假设受益者都是亲(而不是半亲)兄弟姐妹,从遗传上来说,给亲兄妹的每一盎司食物带来的收益和给后代相同的食物带来的收益是一样的。但这样的前提是其他条件都相同。如果我们想要解释为什么在巢内帮忙只发生于某些物种中,我们就需要审视那些不同点了。
例如,试想一种在中空树木中筑巢的鸟类。因为供应很有限,这些树十分宝贵。如果你是一只父母仍然健在的年轻小鸟,父母很可能占有着一棵这样的中空树木(至少最近它们曾经占有过一棵,要不然你就不会存在了)。因此你很可能生活在一个逐渐繁荣的中空树木中。在这个孵化场诞生的新生婴儿都是你的亲弟弟妹妹,从遗传上来说它们对你而言和你的子女一样亲。如果你独自离开,那么找到另一棵中空树木的概率很低。就算你找到了,你生育的后代们在遗传上来说也不会比你的弟弟妹妹们更亲。同样一份努力,投入到你父母巢穴的价值就会超过投入到建立一个你自己的巢穴。这些情况可能就更青睐兄妹关爱——“在巢内帮忙”。
除了所有这些,某些个体,或是每一个个体都会在某些时候,必须离开并寻找新的中空树木,或是其在该物种中的等价物。要使用第7章中“孵化以及照顾”的术语,其中一些必须负责孵化,否则就没有幼崽以供照顾了!这里要说的并不是“要不然该物种就会灭绝”,而是在一个由纯粹的照顾基因占主导地位的种群,孵化基因就会开始有优势。在社会性昆虫中,生育者的角色由女王和雄性来扮演,它们就是那些离开巢穴进入世界来寻找新的“中空树木”的青年。这也是它们为什么会有翅膀的原因,尽管在蚂蚁中工蚁并没有翅膀。这些生育阶层一生都有其特殊使命。那些在巢内帮忙的鸟类和哺乳动物则采用另外一种方式。每一个个体在生命中的某个阶段(大多是在第一个或前两个成年季)都会成为“工人”,这时它们会帮忙照看弟弟妹妹,而在其生命的其他阶段它都立志成为一名“生殖者”。
那上一个注解所描述的裸鼹鼠又怎么样呢?尽管它们的关注要点中并不包含实质的中空树木,但是它们的存在将这个关注要点或“中空树木理论”带向了极致。它们故事的关键就在于热带草原下食物供应的零散分布。它们的主食是地下的块茎。这些块茎可能会非常巨大也埋藏得非常深。这种植物的单个块茎的重量可能会超过1 000只裸鼹鼠的体重。一旦发现,就可以持续为该裸鼹鼠群提供数月甚至数年的食物。但问题就出在找寻这些块茎的过程中,因为它们随机散布在整个大草原地下。对于裸鼹鼠来说,找寻一个食物来源十分困难,但一旦找到什么都值了。罗伯特·布雷特曾经计算过,如果一只裸鼹鼠想自己去寻找那样一个块茎,它需要挖掘的距离可能会磨光它的牙。一个拥有数英里繁忙巡逻着的洞穴的大型社会性种群则是一个非常有效率的块茎矿场。每一个个体都因作为矿工团队的一员而获益。
一个由数十名工作者合作管理的大型洞穴系统就是一个类似于我们假想的“中空树木”一样的关注要点,一点也不逊色!如果你生活在这样一个繁荣的公共迷宫中,并且你的母亲仍然不断地在其中生育你的弟弟妹妹,那么事实上你想要离开并创建一个家庭的欲望就会很低。就算一些新生幼崽只是半个亲兄妹,“关注要点”理论仍然足够使年轻个体留在家中。
中世纪欧洲贵族, 中国世家大族.
我真实的志向完全在另外一个方向上,我也承认这些志向有点大。我想要主张对于有着微小错误的自我复制实体,一旦它们诞生在宇宙任何一个角落,它们就有了几乎无限的能力。
物理世界基本单位是不是就是类似于这样的复制因子. 只有复制因子才具备 “存在” 这一性质.
在这个世界上,只有我们,我们人类,能够反抗自私的复制因子的暴政。
我结论里透出的乐观主义语调引起了那些觉得这和本书其他部分不一致的批评者的怀疑。某些例子中,批评者是一些教条主义社会生物学家,小心翼翼地保护着遗传影响的重要性。在另一些例子中,批评者来自一个近乎荒谬的相反的极端,那些左翼高级神父小心翼翼地保卫着最心爱的神学偶像。罗斯、卡明和莱文廷的《不在我们的基因里》里有一个专有的怪物叫作“还原论”,而所有最好的还原论者都被认为是“决定论者”,特别是“基因决定论者”。
大脑对于还原论者来说是一个确定的生物体,其性质就产生了我们观察到的行为以及从这些行为中领会到的思想状态或者意图……这样的观点是,或应该是,完全与威尔逊和道金斯的社会生物学原理相符的。然而,要采纳这个观点就会将这些原理引入一个两难境地。首先是争辩对于自由的人,人们觉得毫无吸引力(怨恨、教条化等)的行为是先天存在的。然后开始纠结于对犯罪行为的自由主义道德考量,因为这些行为像其他行为一样是生物上决定好的。为了避免这个问题,威尔逊和道金斯许下了一个自由的愿望,只要我们非常希望,我们就能够摆脱基因对我们的控制……这实质是回归到了难堪的笛卡尔哲学,一个二重性问题。
我认为罗斯和她的同事是在谴责我们在吃蛋糕的时候同时占有着它。要么我们必须是“基因决定论者”,要么我们就相信“自由意志”,我们不能两全其美。但是,在这里我相信我是为了威尔逊教授也是为了我自己而发声,只有在罗斯和她的同事眼中我们才是“基因决定论者”。他们没有理解的(很显然,尽管这很难确定)是我们完全有可能在相信基因对人类行为施加着统计意义上的影响的同时,也相信这样的影响是能够被改变的,比如被其他影响覆盖或逆转。基因肯定对任何一个经由自然选择而进化出的行为模式都有统计意义上的影响。
罗斯和她的同事们大概都同意人类性欲是由自然选择进化而来的吧,就像很多其他经过自然选择进化的东西一样。因此他们就必须得相信存在着影响性欲的基因——就像影响其他所有东西的基因一样。然而他们显然也能够在社交上需要的情况下抑制他们的性欲吧。这和二重性有什么关系?当然没有。这个根本不存在的二重性对我提倡反叛的“反抗那些自私的基因的暴政”没有丝毫影响。我们,这里指的是我们的大脑,已经和我们的基因分开并足够独立去反抗它们了。就像已经提过的一样,我们每一次使用避孕套的时候就走出了反抗的一小步了。没有任何理由不相信我们能够进行更大的反抗。
这反驳感觉有点苍白啊.